Earlier this month, the Department of Health and Human Services released more detailed information than it had before on the age distribution and gender distribution of enrollees in the individual markets serviced by the various Exchanges. What it did not do, however, and what needs to be done in order to better predict the likelihood of significant insurer losses in the Exchanges and, thus, greater pressure on premiums is to release data on the combined age and gender distribution of the enrollees. We don’t know, for example, how many woman aged 35-44 are enrolled in the Exchanges. This finer look at the data is important because, as discussed in a previous post, it is the combination of age and gender that bears a stronger statistical relationship to expected medical expenses. And, while the ACA incompletely compensates for age in its premium rating scheme through dampened age rating, it does not compensate at all for gender.
With the help of Mathematica, I have combined some algebra and some numeric methods to try and reverse engineer out combined distributions of age and enrollment that meet various constraints. I believe I have succeeded in finding a plausible combined distribution that can be used in developing plausible models of the likely extent of adverse selection in the individual health insurance markets under the ACA. I present the result in the table below and the chart below. I then have a “how it was done” technical appendix. My work involves creation of a high dimensional polytope that satisfies the existing data and then a search for points on that polytope that appear most plausible. I have also posted a Mathematica notebook on Dropbox that shows the computation.
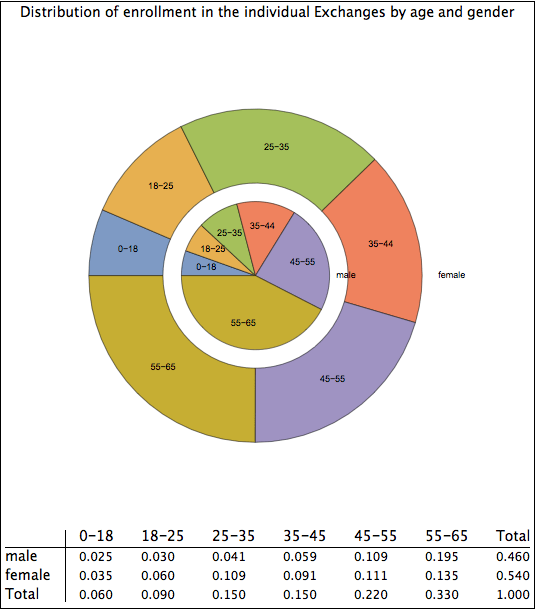
The pie chart above first groups the enrollees by gender. The inner ring shows males and the outer ring shows females. It then groups the enrollees by age bracket. As one can see, women outnumber men significantly in the 18-45 group, are about equal among minors and those between age 45 to 55, and are outnumbered by men in the 55-65 age group.
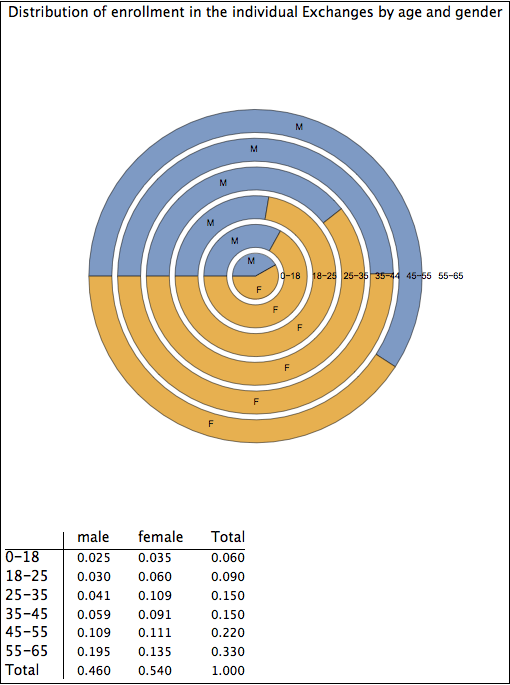
The graphic below shows the same data, but now age is the first grouping mechanism.
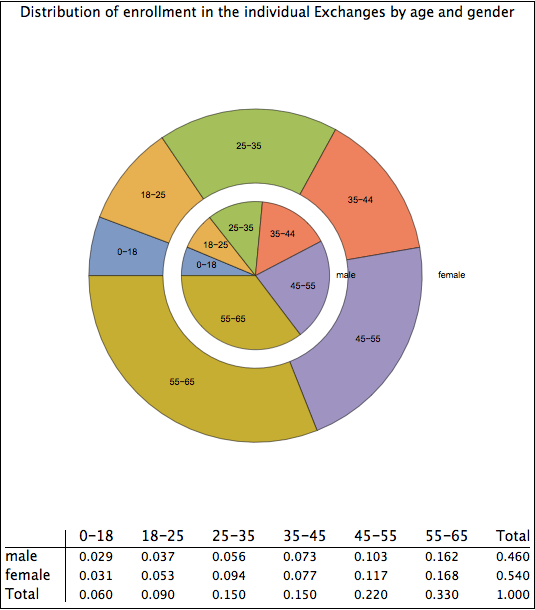
I also attempted to find the combined distribution that would satisfy the observed marginal distributions of age and gender but that would greatly reduce adverse selection. The graphic below thus presents pretty much of a “best case” for the combined age-gender distribution in the Exchanges. Notice that now it is only in the 18-35 year old age brackets that there are substantial variations in the rates of male and female enrollment. I very much doubt that the actual statistics are as promising for ACA success as depicted in the graphic below, but I present them here to show the sensitivity of my methodology to various assumptions.
The next step
The next step in this process is to try to compute the difference between premiums and expenses based on these combined age-gender distributions. I will then compare it to the difference between premiums and expenses based on an age-gender distribution that might have been expected by those who earlier modeled the effects of the ACA. The result should provide some insight into the magnitude of combined age-based and gender-based adverse selection. It should be similar in spirit to the work I showed earlier on this blog here. I hope to have that analysis posted later this week or, I suppose more realistically given my ever pressing day job, early next week.
How it was done
I have essentially 12 variables we are trying to compute: the number of enrollees in the combination of two genders and six age brackets. I know 9 facts about the distribution based on data released by HHS. I know the total number of males and females and I know the total number of persons in each age bracket. And I have 12 constraints on the values: they must all be positive. Using Mathematica’s “Reduce” command, I can use linear algebra to find the polytope that satisfies these equations and inequalities. I get an ugly expression, but it is one Mathematica can work with.
I can then sample 12-dimensions points on the polytope using Mathematica’s “FindInstance” command. I found 2400 points. Each of these points represents an allocation of enrollees among age and gender that satisfies the known constraints. I can then score each point based on its “distance” from my intuition about the strength of adverse selection. That intuition is expressed by “guesstimating” likely ratios between males and females for each of the six age groups. I use a “p-Norm” and Mathematica’s “Norm” command to measure the distance between the six male/female ratios generated by each of the 2400 points and my intuition. I then take the 10 best 12-dimension points and thus obtain a 10x2x6 array. I take the average value of each of the 12 values over all 10 sample points. It is that average that I show in the first two graphics above.
I then permitted the strength of adverse selection to vary by exponentiating the ratios in my intuition. By setting the exponent to zero, I basically try to minimize gender-based adverse selection and keep the gender ratios as close to each other as possible. The results of this effort are shown in the final graphic.
