Set forth below are brief excerpts from my recent blog entry on Risk Adjustment under the Affordable Care Act that has been posted on Forbes The Apothecary. To read the rest, you’ll need to go to that site.
What’s interesting, though, is what happened at almost exactly the same time as I released my Forbes blog entry. New CMS Administrator Andrew Slavitt, whom I noted in the article had actually expressed concern about Risk Adjustment, told Inside Health Policy, an outstanding trade publication, that some changes to the risk adjustment methodology in the draft Notice of Benefit and Payment Parameters for 2017 may instead be implemented in the 2016 plan year. CMS’ proposal calls for the 2017 risk adjustment to use a blended rate from earlier years and account for patient use of preventative services. I know that may not be the sexiest announcement ever made, but it’s important. I’m not going to pretend that my blog entry motivated Mr. Slavitt to start looking hard at CMS methodology — although he would be well educated if he started each day with The Apothecary. But, along with his recent actions taken to reduce the ability of insureds to game the Special Enrollment Period, Administrator Slavitt’s critical attention to Risk Adjustment suggest a willingness to take a fresh look at Obamacare implementation failings.
The Affordable Care Act originally appeared to promise a choice of plans on the Exchanges across at least two spectra: the amount of cost sharing an insured would have to assume and the degree of choice the individual would have in selecting their healthcare providers. Although this ability to customize both choice and “metal tier” was generally considered a feature of Obamacare, it has turned out to pose significant issues. And here’s why: plans with the greatest degree of choice (PPOs) and the lowest amount of cost sharing (mostly Platinum) are magnets for the unhealthy. So, unless there’s something to neutralize the extra costs to the insurer created by this “magnetic attraction” or unless insurers can simply decline to offer plans with high choice or low cost sharing, the freedom to select a plan in fact becomes destructive.
The choice touted by proponents of Obamacare induces a weakened form of an adverse selection death spiral. The whole system may not immediately collapse, but the system’s physics becomes highly unstable. The plans most attractive to the unhealthy become unavailable. The unavailability occurs either because insurers can’t persuade regulators to let them charge the high rates needed to break even or because all but the sickest insured’s won’t buy them at such a price. The most expensive 20% of individual insureds, after all, cost on average more than 60 times as much per person as the least expensive 50%. The Platinum refugees then migrate to the second most attractive plans — in our case often Gold or Silver. (Remember Silver plans have low cost sharing for poor families). But then these plans become disproportionately populated by the sick and can also become considerably more expensive. If there is a point of stability, it is likely to be one in which there is far less choice of physician and far more cost sharing than originally contemplated. Most people might end up in a Bronze HMO.
…
The stability of Obamacare likely rests significantly on the arcane and challenging technology of Risk Adjustment. Run it poorly in ways insurers can game and look for the market to fall into a Bronze HMO basin of attraction or collapse altogether. Run it without the strictest safeguards for medical privacy and see a mass rebellion from insureds. Obamacare would have a better chance at stability with a diversity of plans if Risk Adjustment worked considerably better than has so far been the case.
Experts who have taken a look at the Affordable Care Act have separately considered the effects of three possible sources of unexpected losses by insurers selling policies in the individual Exchanges: purchasers being older than originally projected, more purchasers being women than originally projected, and purchasers having poorer health than originally projected. And, at least with respect to the potential for age-based problems, the prestigious Kaiser Family Foundation has given supporters of the ACA considerable comfort by saying, worst case, older purchasers might result in only a 2.5% increase in insurer costs. But no one to my knowledge — until now — has carefully considered the combined effects of these three sources of potential cost increases and, most likely, pressure for future premium increases.
I have now made an effort to consider the effects of these three sources of insurer losses acting together. Based on that effort, which represents the culmination of work over the past month, I believe it quite possible that insurer losses could amount to 10%, approximately 4% due to purchasers being older than expected, 1% due to greater purchases by women, particularly those in their 20s and 30s, and another 5% due to purchasers having poorer health than expected.
There are four major caveats that should be emphasized up front. (1) These figures are estimates with large error bars; and anyone pretending to great exactitude in this field, particularly as much of the best data is not yet available, is, I suspect, likely pursuing more of a political agenda than a scholarly one. Losses could be close to zero; losses could be in the 15% range. Still, as I am going to show, significant losses are a serious possibility. (2) These losses are computed without consideration of “risk corridors” under section 1342 of the Affordable Care Act. That provision basically calls on taxpayers to pay insurers losing money on the Exchanges a significant subsidy. After consideration of Risk Corridors, average net insurer losses could range anywhere from close to zero to around 6%-7%. (3) These are national figures. There are states such as West Virginia in which the age distribution is considerably worse right now than it is nationally. One should not expect any of the rates of insurer losses (or profits) to be uniform across states or, indeed, across insurers. The figures developed here are an attempt at a rough average. (4) The figures are based on the last full release of data by HHS on enrollment in the Exchanges; if matters change and, for example, the proportion of younger enrollees grows or the proportion of men grows, the loss rates I project here are likely to decline.
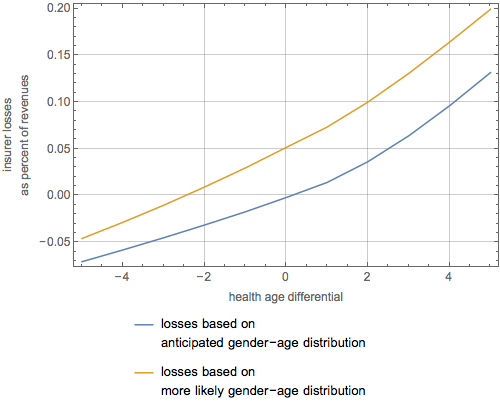
The graphic below summarizes my conclusions. It shows insurer losses (or gains) as a function of a “health age differential” under two scenarios. By health age differential I mean the difference in ages between someone who has the expected health expenses of the actual enrollee and the chronological age of the enrollee. Thus, if an enrollee was actually 53 but had the health expenses of an average 57 year old, their health age differential would be 4. If they had the health expenses of a 50 year old, their health age differential would be negative 3. The yellow line shows insurer losses as a function of the health age differential assuming that the joint distribution of gender and age stays the way it was when HHS last released data. The blue line shows insurer losses as a function of the health age differential assuming that the joint distribution of gender and age ends up the way it was originally projected to be. As enrollment under the ACA increases and the proportion of younger enrollees increases, one might expect the ultimate relationship to head from the yellow line down to the blue line. My assertion that losses could well be 10% is based on the assumption that the joint distribution of gender and age stays the way it is now but that the health of enrollees is equivalent, on average, to those 2 years older than their chronological age. An assumption that enrollees could have health equivalent, on average, to those 4 years older than their chronological age, yields insurer losses of greater than 15% assuming the current joint distribution stays in place and about 10% assuming the original distribution ends up being correct.
The graphic above is useful because it gives what hitherto had been missing in discussions of problems in the individual Exchanges: some sense of the relative magnitude of problems created by age-based adverse selection (older people enrolling disproportionately) and health-based adverse selection (sicker people enrolling disproportionately). Roughly speaking, the degree of price increases induced by the current age and gender imbalances is roughly equivalent to what would occur if the health of the enrollees was, on average, equivalent to those of persons 2.5 years old than they actually are.
So what does it all mean?
At some point, a journalist is likely to ask me what this all means? Is there going to be a death spiral? I would say we are right on the cusp. Losses of 10% by insurers relative to expectations, coupled with whatever increase results from medical inflation, isn’t so enormous that I could say, yes, for sure we are heading into a death spiral. But neither is it such a small number that the risk can be ignored. Moreover, as noted above, the 10% figure is a national average and we need to reduce it because of risk corridors. In some states, however, where the age and gender figures may be worse or the health of enrollees is particularly problematic or where insurers just bid too low and the winner’s curse overtakes them, I still believe there is a substantial risk of a serious problem. In other states, where age and gender figures are better or insurers more accurately forecast the health of their enrollees, the risk of a death spiral is minimal. And, of course, the more people that actually end up purchasing policies in the Exchanges over the next few months, regardless of whether they come from the ranks of the previously uninsured or those who find that they can not keep their current policies, the more stable the system of insurance created by the ACA is likely to be.
So, after a lot of research, I feel more confident than ever in giving a lawyer’s answer — it all depends — and a cliche — we’re not out of the woods yet.
Computation details
The results obtained here are based on essentially the same data as user by the Kaiser Family Foundation, which includes data on the relation between age and premium under typical plans, data from the Society of Actuaries (SOA), also used by Kaiser, on the relation between gender, age and expected medical expenses, and my own prior work attempting, based on data from the Department of Health and Human Services released earlier this month, to derive a joint distribution of enrollment in the individual Exchanges based on age and gender. And, although the math can get a little complicated, the basic idea behind the computations is not all that difficult. It is essentially the computation of some complicated weighted averages. Each combination of gender and age has some expected level of insurance cost (computed by the Society of Actuaries based on commercial insurance data) and some expected premium (computed by Kaiser based on a study of the ACA). Thus, if we know the joint distribution of gender and age, we can weight each of those costs and each of those premiums properly.
There are three areas of the computation that prove most challenging. First, because HHS has not released all of the needed data, one must develop a plausible method of moving from the marginal distributions that were provided by HHS on enrollment by age and enrollment by gender into a joint distribution by gender and age. Second, one must calibrate the SOA cost data and the Kaiser premium data, which are expressed in somewhat different units, such that, if the joint distribution of gender and age was as was originally expected an insurer would just break even. And, third, one must develop a reasonable method of modeling insured populations that are drawn disproportionately from persons who have higher medical expenses. I believe I have now come up with reasonable solutions to all three issues.
Solution #1
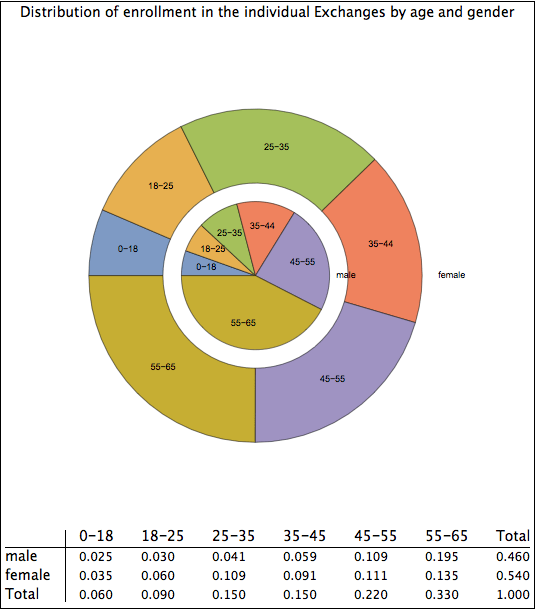
The solution to the first issue, moving from a marginal distribution to a joint distribution, was detailed in my prior blog entry. In short, one finds a large sample of possible joint distributions that match the marginal distributions and scores them according to how well they match the property that people who are subsidized more likely to enroll. One takes an average of a set of solutions that score best. There is an element of judgment in this process on the degree to which individuals respond to subsidization incentives and, all I can say, is that I believe my methodology is reasonable, avoiding the pitfall of thinking that subsidization is irrelevant or of thinking that it is the only factor that matters in determining enrollment rates. I present again what I believe to be the most likely joint distribution of enrollment by gender and age.
Plausible age/gender distribution of ACA enrollees
Solution #2
The solution to the second problem is obtained using calculus and numeric integration. One computes the expected costs and expected premiums given the original joint distribution of enrollees, which is taken to be a product distribution of which one distribution is a “Bernoulli Distribution” in which the probability of being a male or female is equal and the other is a “Mixture Distribution” in which the weights are those shown below (and taken from the Kaiser Family Foundation web site) and the components are discrete uniform distributions over the associated age ranges.
Original estimate of age distribution of enrollees
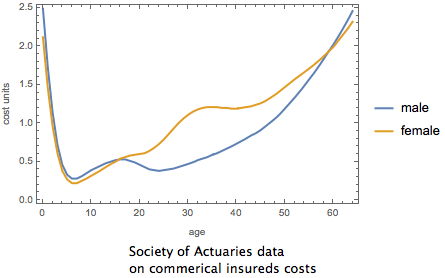
The Society of Actuary data on the relationship between age, gender and medical costs is shown here.
Society of Actuaries data on gender, age and commercial insured expense
The premiums under the ACA are shown here.
ACA Premiums
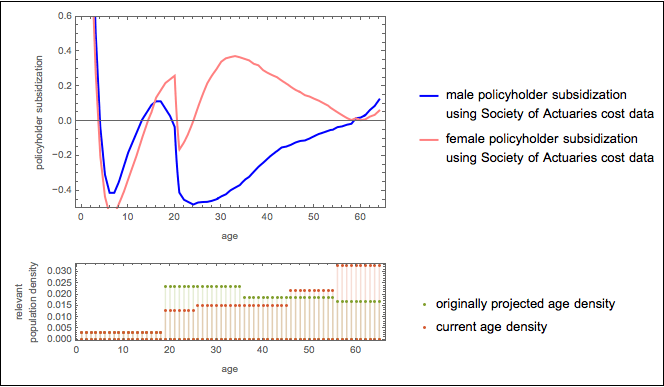
These two plots combined can give us a subsidization rate plot by gender and age. It is shown below along with an associated plot showing the distribution of enrollees by age as was originally assumed and as appears to be the case.
Subsidization rates by gender and age along with anticipated and current age distribution of enrollees
Solution #3
To model adverse selection based on expensive medical conditions, I simply added a health age differential to the insureds. That is, in computing expected medical costs, I assumed that people were their actual age plus or minus some factor. (Ages after this addition were constrained to lie between 0 and 64). The graphic above showed insurer losses as a function of this “health age differential” under two scenarios.
Technical Note
A Mathematica notebook containing the computations used in this blog entry is available . here on Dropbox. I’m also adding a PDF version of the notebook here. I want to thank Sjoerd C. de Vries for coming up with an elegant method within Mathematica of describing the joint distribution used in the computations of various integrals. I am responsible for any mistakes in implementation of this method and my use of Mr. de Vries idea implies nothing about whether he agrees, disagrees or does not care about any of the analyses or opinions in this post.
That might be how the National Enquirer would title this blog entry. And, hey, if mimicking its headline usage attracts more readers than “Reconstructing mixture distributions with a log normal component from compressed health insurance claims data,” why not just take a hint from a highly read journal? But seriously, it’s time to continue delving into some of the math and science behind the issues with the Affordable Care Act. And, to do this, I’d like to take a glance at a valuable data source on modern American health care, the data embedded in the Actuarial Value Calculator created by our friends at the Center for Consumer Information and Insurance Oversight (CCIIO).
This will be the first in a series of posts taking another look at the Actuarial Value Calculator (AVC) and its implications on the future of the Affordable Care Act. (I looked at it briefly before in exploring the effects of reductions in the transitional reinsurance that will take effect in 2015). I promise there are yet more important implications hidden in the data. What I hope to show in my next post, for example, is how the data in the Actuarial Value Calculator exposes the fragility of the ACA to small variations in the composition of the risk pool. If, for example, the pool of insureds purchasing Silver Plans has claims distributions similar to those that were anticipated to purchase Platinum Plans, the insurer might lose more than 30% before Risk Corridors were taken into account and something like 10% even after Risk Corridors were taken into account. And, yes, this takes account of transitional reinsurance. That’s potentially a major risk for the stability of the insurance markets.
What is the Actuarial Value Calculator?
The AVC is intended as a fairly elaborate Microsoft Excel spreadsheet that takes embedded data and macros (essentially programs) written in Visual Basic, and is intended to help insurers determine whether their proposed Exchange plans conform to the requirements for the various “metal tiers” created by the ACA. These metal tiers in turn attempt to quantify the ratio of the expected value of the benefits paid by the insurer to the expected value of claims covered by the policy and incurred by insureds. The programs, I will confess, are a bit inscrutable — and it would be quite an ambitious (and, I must confess, tempting) project to decrypt their underlying logic — but the data they contain is a more accessible goldmine. The AVC contains, for example, the approximate distribution of claims the government expects insurers writing plans in the various metal tiers to encounter.
There are serious limitations in the AVC, to be sure. The data exposed has been aggregated and compressed; rather than providing the amount of actual claims, the AVC has binned claims and then simply presented the average claim within each bin. This space-saving compression is somewhat unfortunate, however, because real claims distributions are essentially continuous. Everyone with annual claims between $600 and $700 does not really have claims of $649. This distortion of the real claims distribution makes it more challenging to find analytic distributions (such as variations of log normal distributions or Weibull distributions) that can depend on the generosity of the plan and that can be extrapolated to consider implications of serious adverse selection. It’s going to take some high-powered math to unscramble the egg and create continuous distributions out of data that has had its “x-values” jiggled. Moreover, there is no breakdown of claim distributions by age, gender, region or other factors that might be useful in trying to predict experience in the Exchanges. (Can you say “FOIA Request”?)
This blog entry is going to make a first attempt, however, to see if there aren’t some good analytic approximations to the data that must have underlain the AVC. It undertakes this exercise in reverse engineering because once we have this data, we can make some reasonable extrapolations and examine the resilience — or fragility — of the system created by the Affordable Care Act. The math may be a little frightening to some, but either try to work with me and get it or just skip to the end where I try to include a plain English summary.
The Math Stuff
1. Reverse engineering approximate continuous approximations to the data underlying the Actuarial Value Calculator
Nothwithstanding the irritating compression of data used to produce the AVC, I can reconstruct a mixture distribution composed mostly of truncated exponential distributions that well approximates the data presented in the AVC. I create one such mixture distribution for each metal tier. I use distributions from this family because they have been proven to be “maximum entropy distributions“, i.e. they contain the fewest assumptions about the actual shape of the data. The idea is to say that when the AVC says that there were 10,273 claims for silver-like policies between $800 and $900 and that they averaged $849.09, that average could well have been the result of an exponential distribution that has been truncated to lie between $800 and $900. With some heavy duty math, shown in the Mathematica notebook available here, we are able, however, to find the member of the truncated exponential family that would produce such an average. We can do this for each bin defined by the data, resorting to uniform distributions for lower values of claims.
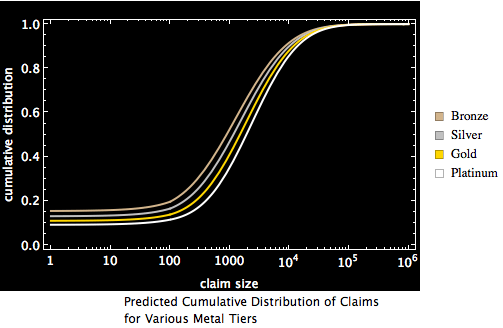
The result of this process is a messy mixture distribution, one for each metal tier. The number of components in the distribution is essentially the same as the number of bins in the AVC data. This will be our first approximation of “the true distribution” from which the claims data presented in the AVC calculator derives. The graphic below shows the cumulative density functions (CDF) for this first approximation. (A cumulative density function shows, for each value on the x-axis the probability that the value of a random draw from that distribution will be less than the value on the x-axis). I present the data in semi-log form: claim size is scaled logarithmically for better visibility on the x-axis and percentage of claims less than or equal to the value on the x-axis is shown on the y-axis.
CDF of the four tiers derived from the first approximation of the data in the AVC
There are two features of the claims distributions that are shown by these graphics. The first is that the distributions are not radically different. The model suggests that the government did not expect massive adverse selection as a result of people who anticipated higher medical expenses to disproportionately select gold and platinum plans while people who anticipated lower medical expenses to disproportionately select bronze and silver plans. The second is that, when viewed on a semi-logarithmic scale, the distributions for values greater than 100 look somewhat symmetric about a vertical axis. They look as if they derive from some mixture distribution composed of a part that produces a value close to zero and something kind of log normalish. If this were the case, it would be a comforting result, both because such mixture distributions would be easy to parameterize and extrapolate to lesser and greater forms of adverse selection and because such mixture distributions with a log normal component are often discussed in the literature on health insurance.
2. Constructing a single Mixture Distribution (or Spliced Distribution) using random draws from the first approximation
One way of finding parameterizable analytic approximations of “the true distribution” is to use our first approximation to produce thousands of random draws and then to use mathematical (and Mathematica) algorithms to find the member of various analytic distribution families that best approximate the random draws. When we do this, we find that the claims data underlying each of the metal tiers is indeed decently approximated by a three-component mixture distribution in which one component essentially produces zeros and the second component is a uniform distribution on the interval 0.1 to 100 and the third component is a truncated log normal distribution starting at 100. (This mixture distribution is also a “spliced distribution” because the domains of each component do not overlap). This three component distribution is much simpler than our first approximation, which contains many more components.
We can see how good the second-stage distributions are by comparing their cumulative distributions (red) to histograms created from random data drawn from the actuarial value calculator (blue). The graphic below show the fits to look excellent.
Note: I do not contend that a mixture distribution with a log normal distribution perfectly conforms to the data. It is, however, pretty good for practical computation.
Actual v. Analytic distributions for various metal tiers
3. Parameterizing health claim distributions based on the actuarial value
The final step here is to create a function that describes the distribution of health claims as a function of a number (v) greater than zero. The concept is that, when v assumes a value equal to the actuarial value of one of the metal tiers, the distribution that results mimics the distribution of AVC-anticipated claims for that tier. By constructing such a function, instead of having just four distributions, I obtain an infinite number of possible distributions. These distributions collapse as special cases to the actual distribution of health care claims produced by the AVC. This process enables us to describe a health claim distribution and to extrapolate what can happen if the claims experience is either better (smaller) than that anticipated for bronze plans or worse (higher) than that anticipated for platinum plans. One can also use this process to compute statistics of the distribution as a function of v such as mean and standard deviation.
Here’s what I get.
Mixture distribution as a function of the actuarial value parameter v
Here is a animation showing, as a function of the actuarial value parameter v, the cumulative distribution function of this analytic approximation to the AVC distribution.
Cumulative distribution of claims by “actuarial value”
One can see the cumulative distribution function sweeping down and to the right as the actuarial value of the plan increases. This is as one would expect: people with higher claims distributions tend to separate themselves into more lavish plans.
Note: I permit the actuarial value of the plan to exceed 1. I do so recognizing full well that no plan would ever have such an actuarial value but allow myself to ignore this false constraint. It is false because what one is really doing is showing a family of mixture distributions in which the parameter v can mathematically assume any positive value but calibrated such that (a) at values of 0.6, 0.7, 0.8 and 0.9 they correspond respectively with the anticipated distribution of health care claims found in the AVC for bronze, silver, gold and platinum plans respectively and (b) they interpolate and extrapolate smoothly and, I think, sensibly from those values.
The animation below presents largely the same information but uses the probability density function (PDF) rather than the sigmoid cumulative distribution function. (If you don’t know the difference, you can read about it here.) I do so via a log-log plot rather than a semi-log plot to enhance visualization. Again, you can see that the right hand segment of the plot is rather symmetric when plotted using a logarithmic x-axis, which suggests that a log normal distribution is not a bad analytic candidate to emulate the true distribution.
Some initial results
One useful computation we can do immediately with our parameterized mixture distribution is to see how the mean claim varies with this actuarial parameter v. The graphic below shows the result. The blue line shows the mean claim as a function of “actuarial value” without consideration of any reinsurance under section 1341 (18 U.S.C. § 18061) of the ACA. The red line shows the mean claim net of reinsurance (assuming 2014 rates of reinsurance) as a function of “actuarial value.” And the gold line shows the shows the mean claim net of reinsurance (assuming 2015 rates of reinsurance) as a function of “actuarial value.” One can see that the mean is sensitive to the actuarial value of the plan. Small errors in assumptions about the pool can lead to significantly higher mean claims, even with reinsurance figured in.
Mean claims as a function of actuarial value parameter for various assumptions about reinsurance
I can also show how the claims experience of the insurer can vary as a result of differences between the anticipated actuarial value parameter v1 that might characterize the distribution of claims in the pool and the actual actuarial value parameter v2 that ends up best characterizing the distribution of claims in the pool. This is done in the three dimensional graphic below. The x-axis shows the actuarial value anticipated to best characterize an insured pool. The y-axis shows the actuarial value that ends up best characterizing that pool. The z-axis shows the ratio of mean actual claims to mean anticipated claims. A value higher than 1 means that the insurer is going to lose money. Values higher than 2 mean that the insurer is going to lose a lot of money. Contours on the graphic show combinations of anticipated and actual actuarial value parameters that yield ratios of 0.93, 1.0, 1.08, 1.5 and 2. This graphic does not take into account Risk Corridors under section 1342 of the ACA.
What one can see immediately is that there are a lot of combinations that cause the insurer to lose a lot of money. There are also combinations that permit the insurer to profit greatly.
Ratio of mean actual claims to mean expected claims for different combinations of anticipated and actual actuarial value parameters
Plain English Summary
One can use data provided by the government inside its Actuarial Value Calculator to derive accurate analytic statistical distributions for claims expected to occur under the Affordable Care Act. Not only can one derive such distributions for the pools anticipated to purchase policies in the various metal tiers (bronze, silver, gold, and platinum) but one can interpolate and extrapolate from that data to develop distributions for many plausible pools. This ability to parameterize plausible claims distributions becomes useful in conducting a variety of experiments about the future of the Exchanges under the ACA and exploring their sensitivity to adverse selection problems.
Resources
You can read about the methodology used to create the calculator here.
You can get the actual spreadsheet here. You’ll need to “enable macros” in order to get the buttons to work.
The actuarial value calculator has a younger cousin, the Minimum Value Calculator. If one looks at the data contained here, one can see the same pattern as one finds in the Actuarial Value Calculator.
Joke
Probably I should have made the title of this entry “Shocking sex secrets of the actuarial value calculator revealed!” and attracted yet more viewers. I then could have noted that the actuarial value calculator ignores sex (gender) in showing claims data. But that would have been going too far.
Exploring the likely implosion of the Affordable Care Act