That might be how the National Enquirer would title this blog entry. And, hey, if mimicking its headline usage attracts more readers than “Reconstructing mixture distributions with a log normal component from compressed health insurance claims data,” why not just take a hint from a highly read journal? But seriously, it’s time to continue delving into some of the math and science behind the issues with the Affordable Care Act. And, to do this, I’d like to take a glance at a valuable data source on modern American health care, the data embedded in the Actuarial Value Calculator created by our friends at the Center for Consumer Information and Insurance Oversight (CCIIO).
This will be the first in a series of posts taking another look at the Actuarial Value Calculator (AVC) and its implications on the future of the Affordable Care Act. (I looked at it briefly before in exploring the effects of reductions in the transitional reinsurance that will take effect in 2015). I promise there are yet more important implications hidden in the data. What I hope to show in my next post, for example, is how the data in the Actuarial Value Calculator exposes the fragility of the ACA to small variations in the composition of the risk pool. If, for example, the pool of insureds purchasing Silver Plans has claims distributions similar to those that were anticipated to purchase Platinum Plans, the insurer might lose more than 30% before Risk Corridors were taken into account and something like 10% even after Risk Corridors were taken into account. And, yes, this takes account of transitional reinsurance. That’s potentially a major risk for the stability of the insurance markets.
What is the Actuarial Value Calculator?
The AVC is intended as a fairly elaborate Microsoft Excel spreadsheet that takes embedded data and macros (essentially programs) written in Visual Basic, and is intended to help insurers determine whether their proposed Exchange plans conform to the requirements for the various “metal tiers” created by the ACA. These metal tiers in turn attempt to quantify the ratio of the expected value of the benefits paid by the insurer to the expected value of claims covered by the policy and incurred by insureds. The programs, I will confess, are a bit inscrutable — and it would be quite an ambitious (and, I must confess, tempting) project to decrypt their underlying logic — but the data they contain is a more accessible goldmine. The AVC contains, for example, the approximate distribution of claims the government expects insurers writing plans in the various metal tiers to encounter.
There are serious limitations in the AVC, to be sure. The data exposed has been aggregated and compressed; rather than providing the amount of actual claims, the AVC has binned claims and then simply presented the average claim within each bin. This space-saving compression is somewhat unfortunate, however, because real claims distributions are essentially continuous. Everyone with annual claims between $600 and $700 does not really have claims of $649. This distortion of the real claims distribution makes it more challenging to find analytic distributions (such as variations of log normal distributions or Weibull distributions) that can depend on the generosity of the plan and that can be extrapolated to consider implications of serious adverse selection. It’s going to take some high-powered math to unscramble the egg and create continuous distributions out of data that has had its “x-values” jiggled. Moreover, there is no breakdown of claim distributions by age, gender, region or other factors that might be useful in trying to predict experience in the Exchanges. (Can you say “FOIA Request”?)
This blog entry is going to make a first attempt, however, to see if there aren’t some good analytic approximations to the data that must have underlain the AVC. It undertakes this exercise in reverse engineering because once we have this data, we can make some reasonable extrapolations and examine the resilience — or fragility — of the system created by the Affordable Care Act. The math may be a little frightening to some, but either try to work with me and get it or just skip to the end where I try to include a plain English summary.
The Math Stuff
1. Reverse engineering approximate continuous approximations to the data underlying the Actuarial Value Calculator
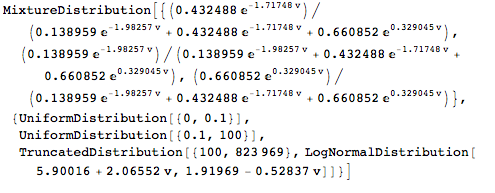
Nothwithstanding the irritating compression of data used to produce the AVC, I can reconstruct a mixture distribution composed mostly of truncated exponential distributions that well approximates the data presented in the AVC. I create one such mixture distribution for each metal tier. I use distributions from this family because they have been proven to be “maximum entropy distributions“, i.e. they contain the fewest assumptions about the actual shape of the data. The idea is to say that when the AVC says that there were 10,273 claims for silver-like policies between $800 and $900 and that they averaged $849.09, that average could well have been the result of an exponential distribution that has been truncated to lie between $800 and $900. With some heavy duty math, shown in the Mathematica notebook available here, we are able, however, to find the member of the truncated exponential family that would produce such an average. We can do this for each bin defined by the data, resorting to uniform distributions for lower values of claims.
The result of this process is a messy mixture distribution, one for each metal tier. The number of components in the distribution is essentially the same as the number of bins in the AVC data. This will be our first approximation of “the true distribution” from which the claims data presented in the AVC calculator derives. The graphic below shows the cumulative density functions (CDF) for this first approximation. (A cumulative density function shows, for each value on the x-axis the probability that the value of a random draw from that distribution will be less than the value on the x-axis). I present the data in semi-log form: claim size is scaled logarithmically for better visibility on the x-axis and percentage of claims less than or equal to the value on the x-axis is shown on the y-axis.
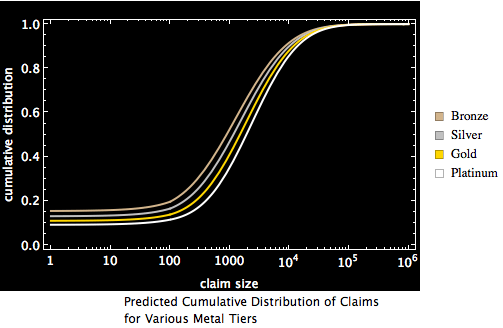
There are two features of the claims distributions that are shown by these graphics. The first is that the distributions are not radically different. The model suggests that the government did not expect massive adverse selection as a result of people who anticipated higher medical expenses to disproportionately select gold and platinum plans while people who anticipated lower medical expenses to disproportionately select bronze and silver plans. The second is that, when viewed on a semi-logarithmic scale, the distributions for values greater than 100 look somewhat symmetric about a vertical axis. They look as if they derive from some mixture distribution composed of a part that produces a value close to zero and something kind of log normalish. If this were the case, it would be a comforting result, both because such mixture distributions would be easy to parameterize and extrapolate to lesser and greater forms of adverse selection and because such mixture distributions with a log normal component are often discussed in the literature on health insurance.
2. Constructing a single Mixture Distribution (or Spliced Distribution) using random draws from the first approximation
One way of finding parameterizable analytic approximations of “the true distribution” is to use our first approximation to produce thousands of random draws and then to use mathematical (and Mathematica) algorithms to find the member of various analytic distribution families that best approximate the random draws. When we do this, we find that the claims data underlying each of the metal tiers is indeed decently approximated by a three-component mixture distribution in which one component essentially produces zeros and the second component is a uniform distribution on the interval 0.1 to 100 and the third component is a truncated log normal distribution starting at 100. (This mixture distribution is also a “spliced distribution” because the domains of each component do not overlap). This three component distribution is much simpler than our first approximation, which contains many more components.
We can see how good the second-stage distributions are by comparing their cumulative distributions (red) to histograms created from random data drawn from the actuarial value calculator (blue). The graphic below show the fits to look excellent.
Note: I do not contend that a mixture distribution with a log normal distribution perfectly conforms to the data. It is, however, pretty good for practical computation.

3. Parameterizing health claim distributions based on the actuarial value
The final step here is to create a function that describes the distribution of health claims as a function of a number (v) greater than zero. The concept is that, when v assumes a value equal to the actuarial value of one of the metal tiers, the distribution that results mimics the distribution of AVC-anticipated claims for that tier. By constructing such a function, instead of having just four distributions, I obtain an infinite number of possible distributions. These distributions collapse as special cases to the actual distribution of health care claims produced by the AVC. This process enables us to describe a health claim distribution and to extrapolate what can happen if the claims experience is either better (smaller) than that anticipated for bronze plans or worse (higher) than that anticipated for platinum plans. One can also use this process to compute statistics of the distribution as a function of v such as mean and standard deviation.
Here’s what I get.
Here is a animation showing, as a function of the actuarial value parameter v, the cumulative distribution function of this analytic approximation to the AVC distribution.

- Cumulative distribution of claims by “actuarial value”

One can see the cumulative distribution function sweeping down and to the right as the actuarial value of the plan increases. This is as one would expect: people with higher claims distributions tend to separate themselves into more lavish plans.
Note: I permit the actuarial value of the plan to exceed 1. I do so recognizing full well that no plan would ever have such an actuarial value but allow myself to ignore this false constraint. It is false because what one is really doing is showing a family of mixture distributions in which the parameter v can mathematically assume any positive value but calibrated such that (a) at values of 0.6, 0.7, 0.8 and 0.9 they correspond respectively with the anticipated distribution of health care claims found in the AVC for bronze, silver, gold and platinum plans respectively and (b) they interpolate and extrapolate smoothly and, I think, sensibly from those values.
The animation below presents largely the same information but uses the probability density function (PDF) rather than the sigmoid cumulative distribution function. (If you don’t know the difference, you can read about it here.) I do so via a log-log plot rather than a semi-log plot to enhance visualization. Again, you can see that the right hand segment of the plot is rather symmetric when plotted using a logarithmic x-axis, which suggests that a log normal distribution is not a bad analytic candidate to emulate the true distribution.

Some initial results
One useful computation we can do immediately with our parameterized mixture distribution is to see how the mean claim varies with this actuarial parameter v. The graphic below shows the result. The blue line shows the mean claim as a function of “actuarial value” without consideration of any reinsurance under section 1341 (18 U.S.C. § 18061) of the ACA. The red line shows the mean claim net of reinsurance (assuming 2014 rates of reinsurance) as a function of “actuarial value.” And the gold line shows the shows the mean claim net of reinsurance (assuming 2015 rates of reinsurance) as a function of “actuarial value.” One can see that the mean is sensitive to the actuarial value of the plan. Small errors in assumptions about the pool can lead to significantly higher mean claims, even with reinsurance figured in.

I can also show how the claims experience of the insurer can vary as a result of differences between the anticipated actuarial value parameter v1 that might characterize the distribution of claims in the pool and the actual actuarial value parameter v2 that ends up best characterizing the distribution of claims in the pool. This is done in the three dimensional graphic below. The x-axis shows the actuarial value anticipated to best characterize an insured pool. The y-axis shows the actuarial value that ends up best characterizing that pool. The z-axis shows the ratio of mean actual claims to mean anticipated claims. A value higher than 1 means that the insurer is going to lose money. Values higher than 2 mean that the insurer is going to lose a lot of money. Contours on the graphic show combinations of anticipated and actual actuarial value parameters that yield ratios of 0.93, 1.0, 1.08, 1.5 and 2. This graphic does not take into account Risk Corridors under section 1342 of the ACA.
What one can see immediately is that there are a lot of combinations that cause the insurer to lose a lot of money. There are also combinations that permit the insurer to profit greatly.

Plain English Summary
One can use data provided by the government inside its Actuarial Value Calculator to derive accurate analytic statistical distributions for claims expected to occur under the Affordable Care Act. Not only can one derive such distributions for the pools anticipated to purchase policies in the various metal tiers (bronze, silver, gold, and platinum) but one can interpolate and extrapolate from that data to develop distributions for many plausible pools. This ability to parameterize plausible claims distributions becomes useful in conducting a variety of experiments about the future of the Exchanges under the ACA and exploring their sensitivity to adverse selection problems.
Resources
You can read about the methodology used to create the calculator here.
You can get the actual spreadsheet here. You’ll need to “enable macros” in order to get the buttons to work.
The actuarial value calculator has a younger cousin, the Minimum Value Calculator. If one looks at the data contained here, one can see the same pattern as one finds in the Actuarial Value Calculator.
Joke
Probably I should have made the title of this entry “Shocking sex secrets of the actuarial value calculator revealed!” and attracted yet more viewers. I then could have noted that the actuarial value calculator ignores sex (gender) in showing claims data. But that would have been going too far.
