I’ve written before that net premium increases for many individuals purchasing policies under the ACA will be higher than gross premium increases. I’ve gotten some emails expressing puzzlement over this conclusion. So, in this post I want to explain in some detail why this is the case.
An example
Consider five Silver policies on an Exchange. In 2015, here is a table showing their gross premiums
1. $4,161.55
2. $3,881.27
3. $4,338.10
4. $4019.11
5. $3550.64
So, the second lowest silver policy is Policy 2, which has a premium of $3,881.27. Suppose our individual can contribute $1,000 per year based on their income. If they had purchased policy 2 their tax credit would have been $2,881.27 and their net premium would have been $1,000. If our individual purchases policy 4, however, which has a gross premium of $4,019.11, their tax credit is still $2,881.27, so they will end up having a net premium of $1,137.84
Now, suppose the gross premium increases average about 6.33% but are distributed as follows among our 5 insurers.
1. 11.38%
2. -2.57%
3. 7.26%
4. 10.28%
5. 5.29%
The new gross premiums for 2016 are thus as follows:
1. $4,634.99
2. $3,781.70
3. $4,652.87
4. $4,432.30
5. $3,738.41
The new second lowest premium is Policy 2, which has a gross premium of $3,781.70. Suppose now our individual has essentially the same income such that the amount they are deemed to be able to contribute is still $1,000. This means the 2016 tax credit is $2,781.70. What if our individual wants to keep his health plan and stick with Policy 4. Maybe our individual likes the practitioners in the Policy 4 network. The new difference between the new gross premium for Policy 4 ($4,432.30) and the tax credit of $2,781.70 is $1,650.60.
Thus, although the gross premium for the policy has gone up 10.28% (bad enough) the net premium has gone up 45.06%.
So, did I concoct some bizarre set of numbers so that the ACA would look bad? I did not. The result you are seeing is baked into the ACA.
An experiment
Let’s run the following experiment. Suppose premiums are normally distributed around $4,000 with a standard deviation of $500. And suppose the gross premium increase is uncorrelated with premiums and is normally distributed around 5% with a standard deviation of 5%. Assume there are five policies at issue. We can then calculate for each of the five policies, the gross premium increase and the net premium increase in the same way we did in the example above. We run this experiment 100 times.
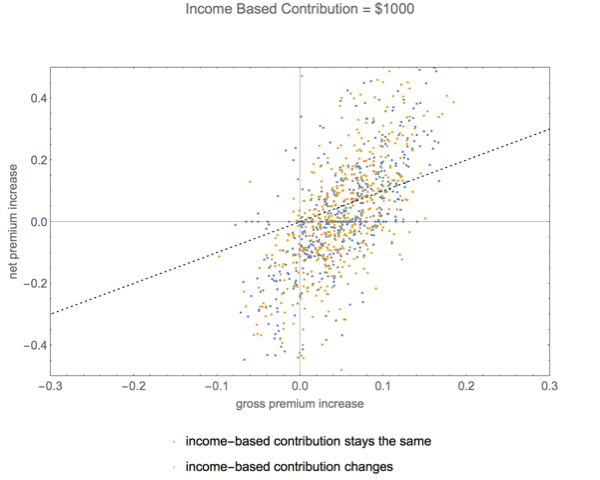
The graphic below shows the results. The horizontal x-axis shows the size of the gross premium increase (in fractions, not percent). And the vertical y-axis shows the size of the net premium increase. The dotted line shows scenarios in which the gross premium increase is the same as the net premium increase. What we can see is that for the larger gross premium increases, the net premium increases tends to be larger than the gross premium increases and for the smaller gross premium increases (or for gross premium decreases), the net premium increase tends to be smaller than the gross premium increase. Thus, about half the population will experience net premium increases larger — and sometimes way larger — than they might think from reading the news.
Is this result an artifact of, say, having our policyholder being deemed by the government to be able to contribute $1,000 based on their income? Not really. The graphic below runs the same experiment but this time assumes our individual is poorer and is thus deemed able to contribute only $500.
What we can see from the graphic is that the result is even more dramatic. The poor will see drastic divergences between gross premium increases and net premium increases. Many, for example who have gross premium increases of say just 5% experience net premium increases of over 30%.
And what of the less subsidized purchasers, those who, for example, are deemed able to contribute $3,000 towards a policy? The graphic below shows the result.
Now we can see that the gross premium increases and net premium increases are clustered pretty tightly together. Indeed, for the wealthier purchasers, net premium increases more often than not are smaller than gross premium increases. However, since most purchasers of Exchange policies tend to be those receiving large subsidies, the graphic above is not representative of the situation for most purchasers.
Did I rig the result by assuming that the income-based contribution stayed the same. No. Here’s a graphic showing gross versus net premiums first, under the assumption that income-based contributions remain the same and second, under the assumption that income-based contributions wander, sometimes going up, sometimes going down.
What you can see is there is not much difference between the yellow points — income based contribution remains the same — and the blue points — income based contribution wanders.
And, although I won’t lengthen this post with yet more graphics, the basic result generalizes to situations in which there are more than 5 Silver policies. The pattern is the same.
Conclusion
It really is true. Net premium increases will often be larger than gross premium increases, particularly for the poor. The sticker shock some received on seeing the gross premium increase figures recently released at healthcare.gov will, in many instances, be little compared to the knockout blow that will occur when people start computing their new net premiums.
Experts who have taken a look at the Affordable Care Act have separately considered the effects of three possible sources of unexpected losses by insurers selling policies in the individual Exchanges: purchasers being older than originally projected, more purchasers being women than originally projected, and purchasers having poorer health than originally projected. And, at least with respect to the potential for age-based problems, the prestigious Kaiser Family Foundation has given supporters of the ACA considerable comfort by saying, worst case, older purchasers might result in only a 2.5% increase in insurer costs. But no one to my knowledge — until now — has carefully considered the combined effects of these three sources of potential cost increases and, most likely, pressure for future premium increases.
I have now made an effort to consider the effects of these three sources of insurer losses acting together. Based on that effort, which represents the culmination of work over the past month, I believe it quite possible that insurer losses could amount to 10%, approximately 4% due to purchasers being older than expected, 1% due to greater purchases by women, particularly those in their 20s and 30s, and another 5% due to purchasers having poorer health than expected.
There are four major caveats that should be emphasized up front. (1) These figures are estimates with large error bars; and anyone pretending to great exactitude in this field, particularly as much of the best data is not yet available, is, I suspect, likely pursuing more of a political agenda than a scholarly one. Losses could be close to zero; losses could be in the 15% range. Still, as I am going to show, significant losses are a serious possibility. (2) These losses are computed without consideration of “risk corridors” under section 1342 of the Affordable Care Act. That provision basically calls on taxpayers to pay insurers losing money on the Exchanges a significant subsidy. After consideration of Risk Corridors, average net insurer losses could range anywhere from close to zero to around 6%-7%. (3) These are national figures. There are states such as West Virginia in which the age distribution is considerably worse right now than it is nationally. One should not expect any of the rates of insurer losses (or profits) to be uniform across states or, indeed, across insurers. The figures developed here are an attempt at a rough average. (4) The figures are based on the last full release of data by HHS on enrollment in the Exchanges; if matters change and, for example, the proportion of younger enrollees grows or the proportion of men grows, the loss rates I project here are likely to decline.
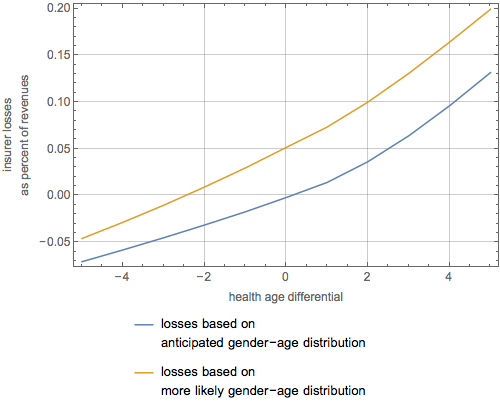
The graphic below summarizes my conclusions. It shows insurer losses (or gains) as a function of a “health age differential” under two scenarios. By health age differential I mean the difference in ages between someone who has the expected health expenses of the actual enrollee and the chronological age of the enrollee. Thus, if an enrollee was actually 53 but had the health expenses of an average 57 year old, their health age differential would be 4. If they had the health expenses of a 50 year old, their health age differential would be negative 3. The yellow line shows insurer losses as a function of the health age differential assuming that the joint distribution of gender and age stays the way it was when HHS last released data. The blue line shows insurer losses as a function of the health age differential assuming that the joint distribution of gender and age ends up the way it was originally projected to be. As enrollment under the ACA increases and the proportion of younger enrollees increases, one might expect the ultimate relationship to head from the yellow line down to the blue line. My assertion that losses could well be 10% is based on the assumption that the joint distribution of gender and age stays the way it is now but that the health of enrollees is equivalent, on average, to those 2 years older than their chronological age. An assumption that enrollees could have health equivalent, on average, to those 4 years older than their chronological age, yields insurer losses of greater than 15% assuming the current joint distribution stays in place and about 10% assuming the original distribution ends up being correct.
The graphic above is useful because it gives what hitherto had been missing in discussions of problems in the individual Exchanges: some sense of the relative magnitude of problems created by age-based adverse selection (older people enrolling disproportionately) and health-based adverse selection (sicker people enrolling disproportionately). Roughly speaking, the degree of price increases induced by the current age and gender imbalances is roughly equivalent to what would occur if the health of the enrollees was, on average, equivalent to those of persons 2.5 years old than they actually are.
So what does it all mean?
At some point, a journalist is likely to ask me what this all means? Is there going to be a death spiral? I would say we are right on the cusp. Losses of 10% by insurers relative to expectations, coupled with whatever increase results from medical inflation, isn’t so enormous that I could say, yes, for sure we are heading into a death spiral. But neither is it such a small number that the risk can be ignored. Moreover, as noted above, the 10% figure is a national average and we need to reduce it because of risk corridors. In some states, however, where the age and gender figures may be worse or the health of enrollees is particularly problematic or where insurers just bid too low and the winner’s curse overtakes them, I still believe there is a substantial risk of a serious problem. In other states, where age and gender figures are better or insurers more accurately forecast the health of their enrollees, the risk of a death spiral is minimal. And, of course, the more people that actually end up purchasing policies in the Exchanges over the next few months, regardless of whether they come from the ranks of the previously uninsured or those who find that they can not keep their current policies, the more stable the system of insurance created by the ACA is likely to be.
So, after a lot of research, I feel more confident than ever in giving a lawyer’s answer — it all depends — and a cliche — we’re not out of the woods yet.
Computation details
The results obtained here are based on essentially the same data as user by the Kaiser Family Foundation, which includes data on the relation between age and premium under typical plans, data from the Society of Actuaries (SOA), also used by Kaiser, on the relation between gender, age and expected medical expenses, and my own prior work attempting, based on data from the Department of Health and Human Services released earlier this month, to derive a joint distribution of enrollment in the individual Exchanges based on age and gender. And, although the math can get a little complicated, the basic idea behind the computations is not all that difficult. It is essentially the computation of some complicated weighted averages. Each combination of gender and age has some expected level of insurance cost (computed by the Society of Actuaries based on commercial insurance data) and some expected premium (computed by Kaiser based on a study of the ACA). Thus, if we know the joint distribution of gender and age, we can weight each of those costs and each of those premiums properly.
There are three areas of the computation that prove most challenging. First, because HHS has not released all of the needed data, one must develop a plausible method of moving from the marginal distributions that were provided by HHS on enrollment by age and enrollment by gender into a joint distribution by gender and age. Second, one must calibrate the SOA cost data and the Kaiser premium data, which are expressed in somewhat different units, such that, if the joint distribution of gender and age was as was originally expected an insurer would just break even. And, third, one must develop a reasonable method of modeling insured populations that are drawn disproportionately from persons who have higher medical expenses. I believe I have now come up with reasonable solutions to all three issues.
Solution #1
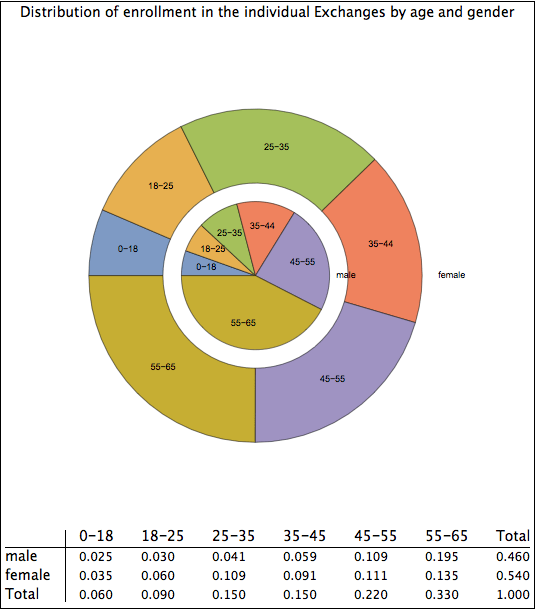
The solution to the first issue, moving from a marginal distribution to a joint distribution, was detailed in my prior blog entry. In short, one finds a large sample of possible joint distributions that match the marginal distributions and scores them according to how well they match the property that people who are subsidized more likely to enroll. One takes an average of a set of solutions that score best. There is an element of judgment in this process on the degree to which individuals respond to subsidization incentives and, all I can say, is that I believe my methodology is reasonable, avoiding the pitfall of thinking that subsidization is irrelevant or of thinking that it is the only factor that matters in determining enrollment rates. I present again what I believe to be the most likely joint distribution of enrollment by gender and age.
Plausible age/gender distribution of ACA enrollees
Solution #2
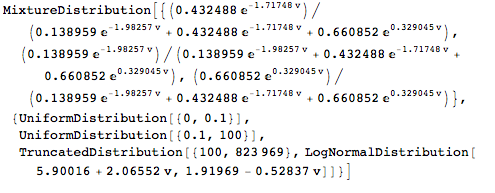
The solution to the second problem is obtained using calculus and numeric integration. One computes the expected costs and expected premiums given the original joint distribution of enrollees, which is taken to be a product distribution of which one distribution is a “Bernoulli Distribution” in which the probability of being a male or female is equal and the other is a “Mixture Distribution” in which the weights are those shown below (and taken from the Kaiser Family Foundation web site) and the components are discrete uniform distributions over the associated age ranges.
Original estimate of age distribution of enrollees
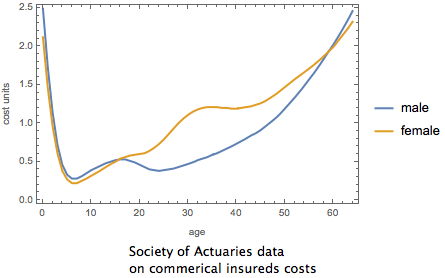
The Society of Actuary data on the relationship between age, gender and medical costs is shown here.
Society of Actuaries data on gender, age and commercial insured expense
The premiums under the ACA are shown here.
ACA Premiums
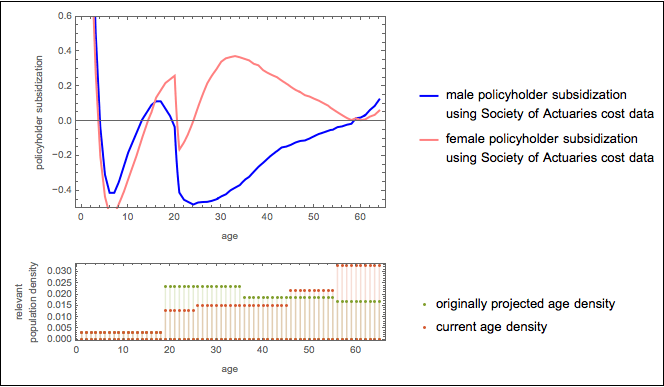
These two plots combined can give us a subsidization rate plot by gender and age. It is shown below along with an associated plot showing the distribution of enrollees by age as was originally assumed and as appears to be the case.
Subsidization rates by gender and age along with anticipated and current age distribution of enrollees
Solution #3
To model adverse selection based on expensive medical conditions, I simply added a health age differential to the insureds. That is, in computing expected medical costs, I assumed that people were their actual age plus or minus some factor. (Ages after this addition were constrained to lie between 0 and 64). The graphic above showed insurer losses as a function of this “health age differential” under two scenarios.
Technical Note
A Mathematica notebook containing the computations used in this blog entry is available . here on Dropbox. I’m also adding a PDF version of the notebook here. I want to thank Sjoerd C. de Vries for coming up with an elegant method within Mathematica of describing the joint distribution used in the computations of various integrals. I am responsible for any mistakes in implementation of this method and my use of Mr. de Vries idea implies nothing about whether he agrees, disagrees or does not care about any of the analyses or opinions in this post.
Earlier this month, the Department of Health and Human Services released more detailed information than it had before on the age distribution and gender distribution of enrollees in the individual markets serviced by the various Exchanges. What it did not do, however, and what needs to be done in order to better predict the likelihood of significant insurer losses in the Exchanges and, thus, greater pressure on premiums is to release data on the combined age and gender distribution of the enrollees. We don’t know, for example, how many woman aged 35-44 are enrolled in the Exchanges. This finer look at the data is important because, as discussed in a previous post, it is the combination of age and gender that bears a stronger statistical relationship to expected medical expenses. And, while the ACA incompletely compensates for age in its premium rating scheme through dampened age rating, it does not compensate at all for gender.
With the help of Mathematica, I have combined some algebra and some numeric methods to try and reverse engineer out combined distributions of age and enrollment that meet various constraints. I believe I have succeeded in finding a plausible combined distribution that can be used in developing plausible models of the likely extent of adverse selection in the individual health insurance markets under the ACA. I present the result in the table below and the chart below. I then have a “how it was done” technical appendix. My work involves creation of a high dimensional polytope that satisfies the existing data and then a search for points on that polytope that appear most plausible. I have also posted a Mathematica notebook on Dropbox that shows the computation.
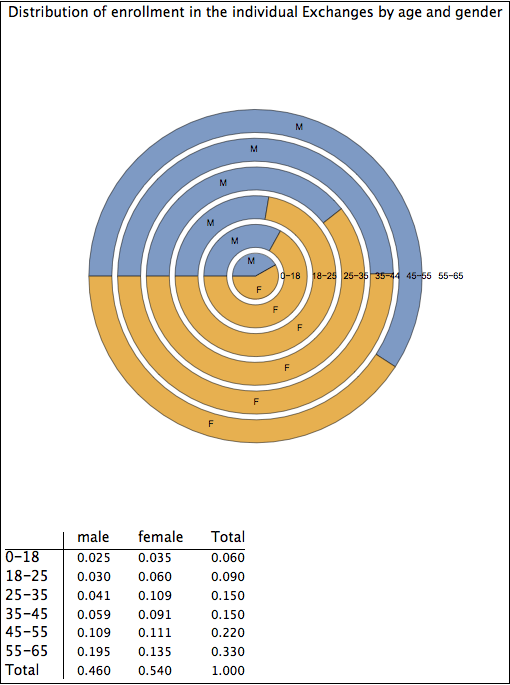
Plausible age/gender distribution of ACA enrollees
The pie chart above first groups the enrollees by gender. The inner ring shows males and the outer ring shows females. It then groups the enrollees by age bracket. As one can see, women outnumber men significantly in the 18-45 group, are about equal among minors and those between age 45 to 55, and are outnumbered by men in the 55-65 age group.
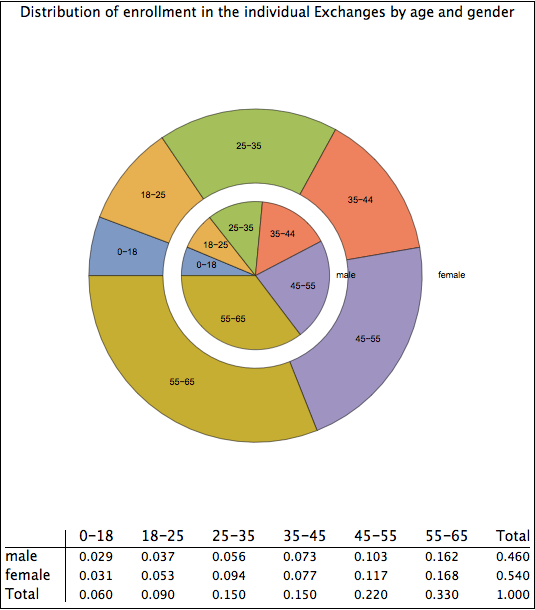
The graphic below shows the same data, but now age is the first grouping mechanism.
I also attempted to find the combined distribution that would satisfy the observed marginal distributions of age and gender but that would greatly reduce adverse selection. The graphic below thus presents pretty much of a “best case” for the combined age-gender distribution in the Exchanges. Notice that now it is only in the 18-35 year old age brackets that there are substantial variations in the rates of male and female enrollment. I very much doubt that the actual statistics are as promising for ACA success as depicted in the graphic below, but I present them here to show the sensitivity of my methodology to various assumptions.
Distribution of enrollees by age and gender that would substantially reduce adverse selection
The next step
The next step in this process is to try to compute the difference between premiums and expenses based on these combined age-gender distributions. I will then compare it to the difference between premiums and expenses based on an age-gender distribution that might have been expected by those who earlier modeled the effects of the ACA. The result should provide some insight into the magnitude of combined age-based and gender-based adverse selection. It should be similar in spirit to the work I showed earlier on this blog here. I hope to have that analysis posted later this week or, I suppose more realistically given my ever pressing day job, early next week.
How it was done
I have essentially 12 variables we are trying to compute: the number of enrollees in the combination of two genders and six age brackets. I know 9 facts about the distribution based on data released by HHS. I know the total number of males and females and I know the total number of persons in each age bracket. And I have 12 constraints on the values: they must all be positive. Using Mathematica’s “Reduce” command, I can use linear algebra to find the polytope that satisfies these equations and inequalities. I get an ugly expression, but it is one Mathematica can work with.
I can then sample 12-dimensions points on the polytope using Mathematica’s “FindInstance” command. I found 2400 points. Each of these points represents an allocation of enrollees among age and gender that satisfies the known constraints. I can then score each point based on its “distance” from my intuition about the strength of adverse selection. That intuition is expressed by “guesstimating” likely ratios between males and females for each of the six age groups. I use a “p-Norm” and Mathematica’s “Norm” command to measure the distance between the six male/female ratios generated by each of the 2400 points and my intuition. I then take the 10 best 12-dimension points and thus obtain a 10x2x6 array. I take the average value of each of the 12 values over all 10 sample points. It is that average that I show in the first two graphics above.
I then permitted the strength of adverse selection to vary by exponentiating the ratios in my intuition. By setting the exponent to zero, I basically try to minimize gender-based adverse selection and keep the gender ratios as close to each other as possible. The results of this effort are shown in the final graphic.
No more than 1% of those with household incomes between 139% and 400% and eligible to select a plan on the individual Exchanges have thus far done so. This is the information about those with middle incomes and lower-middle incomes one can derive from statistics released this week by Health and Human Services. The rate of plan selection among those with incomes over 400% of the federal poverty level is at least 3 times higher than that of persons with middle and lower-middle incomes. It could well be 4 times greater.
No matter how you fine tune the computations, I believe it is fair to say that the middle class is finding the carrots too small and the sticks too small. Some of this may be due to difficulties with the enrollment process rather than the underlying architecture of incentives under the ACA, but either way, most of those eligible to do so, are, at least for now, rejecting the benefit theoretically available to them on the individual Exchanges under the Affordable Care Act.
Visualization
Here are two figures showing the results of my calculations in more detail.
Rates of Take Up
The first graph shows the absolute rates of take up (selection of a plan) among with lower-middle and middle incomes (the lower surface) and the wealthier (the higher surface). The x-axis of the graph shows the assumption one makes about those reasonable eligible to purchase policies. When x is low, one assumes the income distribution of the eligible pool most closely resembles that of persons currently without health insurance. When x is high, one assumes the income distribution of the eligible pool most closely resembles that of persons currently with health insurance form their employer. The y-axis of the graph shows the assumption one makes about the number of persons current with health insurance from their employer who might reasonably be considered eligible to purchase insurance on a health insurance Exchange. A low value of y means that very few of these people should be considered eligible. A high value of y means that 10% of these people should be considered eligible. The z-axis (vertical) shows the fraction of people eligible to do so who have to date selected a policy on an Exchange.
Take Up Rates among the Wealthier (top surface) and the Lower Middle and Middle Income Group (lower surface)
As one can see the values are always less than 1% for the lower-middle and middle incomes. The values for the wealthier depends on the assumptions made but for all values are below 6% and is frequently below 4%. And these are values for selection of a plan, not for actual purchase of a policy. Those numbers are likely to be even smaller due to many people leaving items in their “shopping cart” without paying at the check out counter.
Take Up Ratios
The second graphic shows the ratio between the take up rates among the wealthier and the take up rates among the lower-middle and middle income group. The x and y axes are the same as before. A value of 3.4 on the z-axis means that the take up rate among the wealthy is 3.4 times what it is among the lower-middle and middle income groups. As one can again see the ratio is above 3 for almost all assumptions one could make and is frequently above 4.
Take Up Ratios
Show me the calculation
How do I get to these figures? Algebra. Some of it is very nasty algebra, but I have the world’s best computer algebra system, Mathematica, at my disposal to make the problem much easier. Rather than include the somewhat complex computations directly in this blog post, I’m going to include a PDF file showing the computations and a CDF file (a Mathematica file format). You can read the CDF file either with Mathematica itself or with the free CDF Player available here. The data, by the way comes from a combination of this tidbit of information found on page 7 of the report released by HHS on December 11, 2013, and data from the Urban Institute and Kaiser Foundation.
That might be how the National Enquirer would title this blog entry. And, hey, if mimicking its headline usage attracts more readers than “Reconstructing mixture distributions with a log normal component from compressed health insurance claims data,” why not just take a hint from a highly read journal? But seriously, it’s time to continue delving into some of the math and science behind the issues with the Affordable Care Act. And, to do this, I’d like to take a glance at a valuable data source on modern American health care, the data embedded in the Actuarial Value Calculator created by our friends at the Center for Consumer Information and Insurance Oversight (CCIIO).
This will be the first in a series of posts taking another look at the Actuarial Value Calculator (AVC) and its implications on the future of the Affordable Care Act. (I looked at it briefly before in exploring the effects of reductions in the transitional reinsurance that will take effect in 2015). I promise there are yet more important implications hidden in the data. What I hope to show in my next post, for example, is how the data in the Actuarial Value Calculator exposes the fragility of the ACA to small variations in the composition of the risk pool. If, for example, the pool of insureds purchasing Silver Plans has claims distributions similar to those that were anticipated to purchase Platinum Plans, the insurer might lose more than 30% before Risk Corridors were taken into account and something like 10% even after Risk Corridors were taken into account. And, yes, this takes account of transitional reinsurance. That’s potentially a major risk for the stability of the insurance markets.
What is the Actuarial Value Calculator?
The AVC is intended as a fairly elaborate Microsoft Excel spreadsheet that takes embedded data and macros (essentially programs) written in Visual Basic, and is intended to help insurers determine whether their proposed Exchange plans conform to the requirements for the various “metal tiers” created by the ACA. These metal tiers in turn attempt to quantify the ratio of the expected value of the benefits paid by the insurer to the expected value of claims covered by the policy and incurred by insureds. The programs, I will confess, are a bit inscrutable — and it would be quite an ambitious (and, I must confess, tempting) project to decrypt their underlying logic — but the data they contain is a more accessible goldmine. The AVC contains, for example, the approximate distribution of claims the government expects insurers writing plans in the various metal tiers to encounter.
There are serious limitations in the AVC, to be sure. The data exposed has been aggregated and compressed; rather than providing the amount of actual claims, the AVC has binned claims and then simply presented the average claim within each bin. This space-saving compression is somewhat unfortunate, however, because real claims distributions are essentially continuous. Everyone with annual claims between $600 and $700 does not really have claims of $649. This distortion of the real claims distribution makes it more challenging to find analytic distributions (such as variations of log normal distributions or Weibull distributions) that can depend on the generosity of the plan and that can be extrapolated to consider implications of serious adverse selection. It’s going to take some high-powered math to unscramble the egg and create continuous distributions out of data that has had its “x-values” jiggled. Moreover, there is no breakdown of claim distributions by age, gender, region or other factors that might be useful in trying to predict experience in the Exchanges. (Can you say “FOIA Request”?)
This blog entry is going to make a first attempt, however, to see if there aren’t some good analytic approximations to the data that must have underlain the AVC. It undertakes this exercise in reverse engineering because once we have this data, we can make some reasonable extrapolations and examine the resilience — or fragility — of the system created by the Affordable Care Act. The math may be a little frightening to some, but either try to work with me and get it or just skip to the end where I try to include a plain English summary.
The Math Stuff
1. Reverse engineering approximate continuous approximations to the data underlying the Actuarial Value Calculator
Nothwithstanding the irritating compression of data used to produce the AVC, I can reconstruct a mixture distribution composed mostly of truncated exponential distributions that well approximates the data presented in the AVC. I create one such mixture distribution for each metal tier. I use distributions from this family because they have been proven to be “maximum entropy distributions“, i.e. they contain the fewest assumptions about the actual shape of the data. The idea is to say that when the AVC says that there were 10,273 claims for silver-like policies between $800 and $900 and that they averaged $849.09, that average could well have been the result of an exponential distribution that has been truncated to lie between $800 and $900. With some heavy duty math, shown in the Mathematica notebook available here, we are able, however, to find the member of the truncated exponential family that would produce such an average. We can do this for each bin defined by the data, resorting to uniform distributions for lower values of claims.
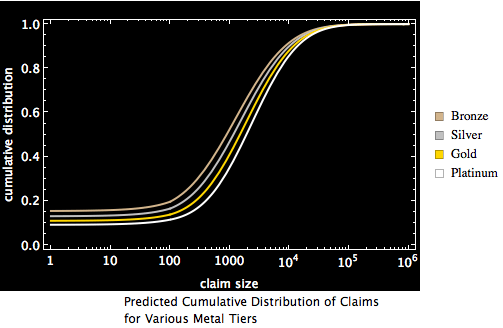
The result of this process is a messy mixture distribution, one for each metal tier. The number of components in the distribution is essentially the same as the number of bins in the AVC data. This will be our first approximation of “the true distribution” from which the claims data presented in the AVC calculator derives. The graphic below shows the cumulative density functions (CDF) for this first approximation. (A cumulative density function shows, for each value on the x-axis the probability that the value of a random draw from that distribution will be less than the value on the x-axis). I present the data in semi-log form: claim size is scaled logarithmically for better visibility on the x-axis and percentage of claims less than or equal to the value on the x-axis is shown on the y-axis.
CDF of the four tiers derived from the first approximation of the data in the AVC
There are two features of the claims distributions that are shown by these graphics. The first is that the distributions are not radically different. The model suggests that the government did not expect massive adverse selection as a result of people who anticipated higher medical expenses to disproportionately select gold and platinum plans while people who anticipated lower medical expenses to disproportionately select bronze and silver plans. The second is that, when viewed on a semi-logarithmic scale, the distributions for values greater than 100 look somewhat symmetric about a vertical axis. They look as if they derive from some mixture distribution composed of a part that produces a value close to zero and something kind of log normalish. If this were the case, it would be a comforting result, both because such mixture distributions would be easy to parameterize and extrapolate to lesser and greater forms of adverse selection and because such mixture distributions with a log normal component are often discussed in the literature on health insurance.
2. Constructing a single Mixture Distribution (or Spliced Distribution) using random draws from the first approximation
One way of finding parameterizable analytic approximations of “the true distribution” is to use our first approximation to produce thousands of random draws and then to use mathematical (and Mathematica) algorithms to find the member of various analytic distribution families that best approximate the random draws. When we do this, we find that the claims data underlying each of the metal tiers is indeed decently approximated by a three-component mixture distribution in which one component essentially produces zeros and the second component is a uniform distribution on the interval 0.1 to 100 and the third component is a truncated log normal distribution starting at 100. (This mixture distribution is also a “spliced distribution” because the domains of each component do not overlap). This three component distribution is much simpler than our first approximation, which contains many more components.
We can see how good the second-stage distributions are by comparing their cumulative distributions (red) to histograms created from random data drawn from the actuarial value calculator (blue). The graphic below show the fits to look excellent.
Note: I do not contend that a mixture distribution with a log normal distribution perfectly conforms to the data. It is, however, pretty good for practical computation.
Actual v. Analytic distributions for various metal tiers
3. Parameterizing health claim distributions based on the actuarial value
The final step here is to create a function that describes the distribution of health claims as a function of a number (v) greater than zero. The concept is that, when v assumes a value equal to the actuarial value of one of the metal tiers, the distribution that results mimics the distribution of AVC-anticipated claims for that tier. By constructing such a function, instead of having just four distributions, I obtain an infinite number of possible distributions. These distributions collapse as special cases to the actual distribution of health care claims produced by the AVC. This process enables us to describe a health claim distribution and to extrapolate what can happen if the claims experience is either better (smaller) than that anticipated for bronze plans or worse (higher) than that anticipated for platinum plans. One can also use this process to compute statistics of the distribution as a function of v such as mean and standard deviation.
Here’s what I get.
Mixture distribution as a function of the actuarial value parameter v
Here is a animation showing, as a function of the actuarial value parameter v, the cumulative distribution function of this analytic approximation to the AVC distribution.
Cumulative distribution of claims by “actuarial value”
One can see the cumulative distribution function sweeping down and to the right as the actuarial value of the plan increases. This is as one would expect: people with higher claims distributions tend to separate themselves into more lavish plans.
Note: I permit the actuarial value of the plan to exceed 1. I do so recognizing full well that no plan would ever have such an actuarial value but allow myself to ignore this false constraint. It is false because what one is really doing is showing a family of mixture distributions in which the parameter v can mathematically assume any positive value but calibrated such that (a) at values of 0.6, 0.7, 0.8 and 0.9 they correspond respectively with the anticipated distribution of health care claims found in the AVC for bronze, silver, gold and platinum plans respectively and (b) they interpolate and extrapolate smoothly and, I think, sensibly from those values.
The animation below presents largely the same information but uses the probability density function (PDF) rather than the sigmoid cumulative distribution function. (If you don’t know the difference, you can read about it here.) I do so via a log-log plot rather than a semi-log plot to enhance visualization. Again, you can see that the right hand segment of the plot is rather symmetric when plotted using a logarithmic x-axis, which suggests that a log normal distribution is not a bad analytic candidate to emulate the true distribution.
Some initial results
One useful computation we can do immediately with our parameterized mixture distribution is to see how the mean claim varies with this actuarial parameter v. The graphic below shows the result. The blue line shows the mean claim as a function of “actuarial value” without consideration of any reinsurance under section 1341 (18 U.S.C. § 18061) of the ACA. The red line shows the mean claim net of reinsurance (assuming 2014 rates of reinsurance) as a function of “actuarial value.” And the gold line shows the shows the mean claim net of reinsurance (assuming 2015 rates of reinsurance) as a function of “actuarial value.” One can see that the mean is sensitive to the actuarial value of the plan. Small errors in assumptions about the pool can lead to significantly higher mean claims, even with reinsurance figured in.
Mean claims as a function of actuarial value parameter for various assumptions about reinsurance
I can also show how the claims experience of the insurer can vary as a result of differences between the anticipated actuarial value parameter v1 that might characterize the distribution of claims in the pool and the actual actuarial value parameter v2 that ends up best characterizing the distribution of claims in the pool. This is done in the three dimensional graphic below. The x-axis shows the actuarial value anticipated to best characterize an insured pool. The y-axis shows the actuarial value that ends up best characterizing that pool. The z-axis shows the ratio of mean actual claims to mean anticipated claims. A value higher than 1 means that the insurer is going to lose money. Values higher than 2 mean that the insurer is going to lose a lot of money. Contours on the graphic show combinations of anticipated and actual actuarial value parameters that yield ratios of 0.93, 1.0, 1.08, 1.5 and 2. This graphic does not take into account Risk Corridors under section 1342 of the ACA.
What one can see immediately is that there are a lot of combinations that cause the insurer to lose a lot of money. There are also combinations that permit the insurer to profit greatly.
Ratio of mean actual claims to mean expected claims for different combinations of anticipated and actual actuarial value parameters
Plain English Summary
One can use data provided by the government inside its Actuarial Value Calculator to derive accurate analytic statistical distributions for claims expected to occur under the Affordable Care Act. Not only can one derive such distributions for the pools anticipated to purchase policies in the various metal tiers (bronze, silver, gold, and platinum) but one can interpolate and extrapolate from that data to develop distributions for many plausible pools. This ability to parameterize plausible claims distributions becomes useful in conducting a variety of experiments about the future of the Exchanges under the ACA and exploring their sensitivity to adverse selection problems.
Resources
You can read about the methodology used to create the calculator here.
You can get the actual spreadsheet here. You’ll need to “enable macros” in order to get the buttons to work.
The actuarial value calculator has a younger cousin, the Minimum Value Calculator. If one looks at the data contained here, one can see the same pattern as one finds in the Actuarial Value Calculator.
Joke
Probably I should have made the title of this entry “Shocking sex secrets of the actuarial value calculator revealed!” and attracted yet more viewers. I then could have noted that the actuarial value calculator ignores sex (gender) in showing claims data. But that would have been going too far.
As discussed yesterday on this blog and elsewhere in the media, Cover California, the state entity organizing enrollment there, has released data showing the age distribution of the group thus far enrolling in plans on its Exchanges. Although I took a rather cautionary tone about the age distribution — fearing it could stimulate adverse selection — the head of Cover California and some influential media outlets generally favorable to the Affordable Care Act have been considerably more cheerful. So, who’s right? For reasons I will now show — and probably to no one’s surprise — me. (More or less).
To do this, we need to do some math. It’s a more sophisticated variant of the back of the envelope computation I undertook earlier on this blog. The idea is to compute the mean profit of insurers in the Exchange as a function of the predicted versus the actual age distribution of the pool they insure. Conceptually, that’s not too difficult. Here are the steps.
1. Compute the premium that equilibrates the “expectation” of premiums and costs for the predicted age distribution of the pool they insure. Call that the “predicted equilibrating premium.”
2. Compute the expected profit of the insurer given the predicted equilibrating premium and the actual age distribution of the pool they insure.
3. Do Step 1 and Step 2 for a whole bunch (that’s the technical term) of combinations of predicted age distributions and actual age distributions.
Moving from concept to real numbers is not so easy. The challenge comes in getting reasonable data and, since there are an infinite number of age distributions and in developing a sensible parameterization of some subset of plausible distributions.
The Data
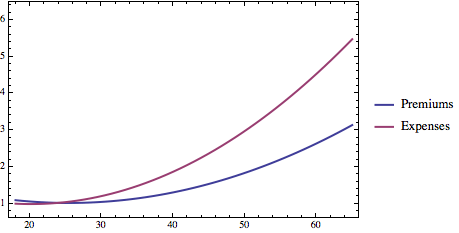
The data is interesting in and of itself. To get the relationship between premiums and age, I used the robust Kaiser Calculator. Since healthcare.gov itself recommends the web site (their own site seems to have a few problems) and I have personally validated its projected premiums for various groups against what I actually see from various vendors, I believe it is about as reliable a source of data as one is likely to find anywhere right now. So, by hitting the Kaiser Calculator with a few test cases and doing a linear model fit using Mathematica (or any other decent statistics package), we are able to find a mathematical function that well captures a (quadratic) relationship between age and premium. (The relationship isn’t “really” quadratic, but quadratics are easy to work with and fit the data very well.) The graphic below shows the result.
Nationwide average health insurance premium for a silver plan as a function of age
We can normalize the graphic and the relationship such that the premium at age 18 (the lowest age I consider) is 1 and everything else is expressed as a ratio of the premium at age 18. Here’s the new graphic. The vertical axis is now just expressed in ratios.
Nationwide average health insurance premium ratio for a silver plan as a function of age
To get the relationship between cost and age, I used a peer reviewed report from Health Services Research titled “The Lifetime Distribution of Health Care Costs.” It’s from 2004 but that should not matter much: although the absolute numbers have clearly escalated since that time, there is no reason to think that the age distribution has moved much. I can likewise do a linear model fit and find a quadratic function that fits well (R^2 = 0.982). Again, I can normalize the function so that its value at age 18 is 1 and everything else is expressed as a ratio of the average costs incurred by someone at age 18. Here’s a graphic showing the both the relationship between age and normalized premiums in the Exchanges under the Affordable Care Act and normalized costs.
The key thing to see is that health care claims escalate at a faster rate than health care premiums. Others have noted this point as well. They do so because the Affordable Care Act (42 U.S.C. § 300gg(a)(1)(A)(iii)) prohibits insurers from charging the oldest people in the Exchanges more than 3 times what they charge the youngest people. Reality, however, is under no such constraint.
Parameterizing the Age Distribution
There are an infinite number of potential age distributions for people purchasing health insurance. I can’t test all of them and I certainly can make a graph that shows profit as a function of every possible combination of two infinite possibilities. But, what I can do — and rather cleverly, if I say so myself — is to “triangulate” a distribution by saying how close it is to the age distribution of California as a whole and how close it is to the age distribution of those currently in the California Exchange pool. I’ll say a distribution has a “Pool Parameter Value” of 0 if it comes purely from California as a whole and has value of 1 if it comes purely from the California Exchange pool. A value of 0.4 means the distribution comes 40% from California as a whole and 60% from the current California Exchange pool. The animation below shows how the cumulative age distribution varies as the Pool Parameter Value changes.
How the age distribution varies as the pool goes from looking more like California as a whole to looking more like the current pool as a whole.
Equilibration and Results
The last step is to compute a function showing the equilibrium premium as a function of the predicted pool parameter value. We can then use this equilibrating premium to compute and graph profit as a function of both predicted pool parameter value and actual pool parameter value.
The figure below shows some of the Mathematica code used to accomplish this task.
Mathematica code used to produce graphic showing relationship between insurer profit in the California exchanges and the nature of the predicted pool and the actual pool
Stare at the graphic at the bottom. What it shows is that if, for example, California insurers based their premiums on the pool having a “parameter value” of 0 (looks like California) and the actual pool ends up having a “parameter value of 1 (looks like the current pool), they will, everything else being equal, lose something like 10% on their policies and probably need to raise rates by about 10% the following year. If, on the other hand, they thought the pool would have a parameter value of 0.5 and it ended up having a parameter value of 0.75 the insurers might lose only about 3.5%.
Bottom Line
If I were an insurer in California I’d be concerned about the age numbers coming in, but not panicked. First, I hope I did not assume that my pool of insureds would look like California as a whole. I had to assume some degree of adverse selection. But it does not look as though, even if I made a fairly substantial error, the losses will be that huge. That’s true without the Risk Corridors subsidies and it is all the more true with Risk Corridor subsidies.
What I would be losing sleep about, however, is that the pool I am getting is composed disproportionately of the sick of all ages. If I underestimated that adverse selection problem, I could be in deep problem. My profound discomfort would arise because, while I get to charge the aged somewhat more, I don’t get to charge the sick anymore. And there’s one fact that would be troubling me. Section 1101 of the Affordable Care Act established this thing calledthe Pre-Existing Condition Insurance Pool. It’s been in existence (losing boatloads of money) for the past three years. It held people who couldn’t get insurance because they had pre-existing conditions. They proved very expensive to insure. There are 16,000 Californians enrolled in that pool. But that pool ends on January 1, 2014. And the people in it have to be pretty motivated to get healthy insurance. Where are they going to go? If the answer is that a good chunk of the 79,000 people now enrolled in the California pool are former members of the PCIP, the insurers are in trouble unless they get a lot more healthy insureds to offset these individuals.
According to a news report from Reuters, which is being picked up widely, early figures from four states are suggesting that the pool of insureds enrolling in the Exchanges is older than anticipated. If this situation persists and is not an artifact of either the particular states involved or simply the urgency with which older people applied, it further threatens the ability of the Affordable Care Act to sustain its plan of equalizing opportunity to acquire health insurance. This is so because, although older people do pay more in the Exchanges established by the Affordable Care Act, they pay less than would be actuarially appropriate. Young people, by contrast, pay more.
Here’s the key passage from the Reuter’s report.
The Obama administration is aiming to enroll about 2.7 million 18- to 35-year-olds in the exchanges by the end of March, out of 7 million total, or about 38 percent.
Early data from Connecticut, Kentucky, Washington and Maryland show that so far more than 20 percent of the 23,500 combined enrollees in private insurance plans are 18 to 34 years old, ranging from about 19 percent in Kentucky and Connecticut to about 27 percent in Maryland. About 36 percent of enrollees across the four states are 55 to 64. Additional demographic data is expected from California on Thursday.
A back of the envelope computation shows that this situation could result in additional losses of about 10% by insurers before risk adjustment payments are taken into account. And this is true even if each age group in the pool is as healthy as anticipated. The insurer losses resulting from disproportionate enrollment of older insureds has several important consequences: (1) insurers may decide to exit the pool in the future; (2) insurers may decide to raise premiums to adjust to the real pool as opposed to the projected pool; and (3) the government is going to pay more in Risk Corridor payments than anticipated.
Relationship between “true ratio”, percent young in the pool, and Exchange insurer profitability
The graphic above attempts to explain the issue. The x-axis shows the “true ratio” of expected medical claims to be paid between the oldest people in the pool and the expected medical claims to be paid of the youngest people in the pool. No one knows this figure for sure, but it could well be about 5 to 1. (This is why the Affordable Care Act is forced to hold premiums to a 3 to 1 ratio; otherwise premiums for the older group would be extremely high.) The y-axis shows the percentage of people entering the Exchange pools who are between 18 and 35. As the Reuters story indicates, it was hoped this group would comprise 38% of the pool. The green dot shows the result that might be hoped for if the young (18-35) indeed constitute 38% of the pool and the true ratio of claims paid between oldest and youngest is 5 to 1. At this level, insurers neither make unusual profits nor suffer unusual losses. The blue dot shows the result that might be seen if the young end up constituting — as the Reuters says the early evidence shows — about 20% of the pool. As one can see the red dot produces losses that are close to 10% of the risk assumed by insurers.
I’m placing a Mathematica notebook on Dropbox showing the computation. The idea, is that one finds a linear relationship between age and premium relationship that just covers claims payments for any value of the true ratio but subject to the constraint that the premium the oldest person pays can not be more than three times bigger than the premium the youngest person pays and under the assumption that those under age 35 constitute 38% of the pool. One then determines profits for any combination of true ratio and percentage of the pool under age 35. The process takes a little algebra (mostly rescaling operations), some calculus (finding “expectations” of distributions) and some visualization.
Notes
1. Although I modeled it that way, I am fully aware that the relationship between age and claims is non-linear. It’s probably more cubic. I’m also fully aware the relationship between age and premiums tends not to be linear under the Affordable Care Act. You can use the wonderful Kaiser Calculator or go to the fabulous Health Sherpa website to see that. And I’m also aware that using a uniform distribution to model the distribution of ages within the 18-35 group and the 35-64 group is imperfect. Still, for purposes of getting just some rapid order of magnitude estimates to guard against those who would dismiss the problem or wildly exaggerate it, I believe the linear assumption is supportable. It keeps things simple in a situation in which one has to be very careful about false assertions of precision and in which predictions are often hideously wrong.
2. As mentioned earlier, if the disproportionate enrollment of the elderly does not persist, as supporters of the ACA hope, the problem identified in this entry is reduced. Other problems, such as disproportionate enrollment of the unhealthy — which is a far more significant issue — may persist. But we don’t have data at present on the health of those enrolling. It is troublesome, however, that most of the time proponents of the ACA trot out someone who has actually enrolled in the Exchanges (or is a Jessica Sanford who thought they would), it is someone who has higher-than-average medical expenses. I wish they would more frequently show off someone who is healthy now but just wants protection against the possibility of an adverse health event.
In a Wall Street Journal op-ed today that tracks much of what has been said on this blog in recent years, Florida Senator Marco Rubio announced that he will introduce later today a bill (provisionally numbered S.1726 ) that would apparently eliminate “Risk Corridors,” the provision of the Affordable Care Act under which the government would reimburse insurers selling insurance on an Exchange for the next three years from a good portion of any losses that they suffer there. Rubio contends that “ObamaCare’s risk corridors are designed in such an open-ended manner that the president’s action now exposes taxpayers to a bailout of the health-insurance industry if and when the law fails.”
Marco Rubio
Senator Rubio is largely correct, I believe, in his understanding of Risk Corridors (section 1342 of the ACA, codified at 42 U.S.C. 18062) both as drafted in the statute and as implemented by the Department of Health and Human Services. Unlike its cousins, the reinsurance provisions (42 U.S.C. § 18061) and the risk adjustment provisions (42 U.S.C. § 18063), both of which likewise help reduce the risks of writing policies for sale on an Exchange, Risk Corridors is not drafted to be budget neutral. That was the way the Congressional Budget Office scored it — it assumed that receipts under the provision would equal outlays — but this was clearly a blunder that should have been apparent at the time and that minimized the advertised budgetary risk entailed by passage of the Affordable Care Act. As discussed in an earlier blog post, if the distribution of profit and loss by insurers selling in the Exchanges is skewed in the loss direction, the government will be obligated to pay out more than it takes in. Where the funding for this new “entitlement” for the insurance industry would come from is unclear. Senator Rubio is thus correct again when he says that the bill will be paid for by the taxpayer.
Senator Rubio is not correct to imply, however, that, standing by itself, the underestimate of Risk Corridor exposure represents this enormous understatement of the cost to the taxpayer of the Affordable Care Act. That law, for better or worse, always called for large taxpayer outlays to help prop up an insurance system that, as one of its critical architectural features, would attack medical underwriting by insurers. Indeed, although it was not apparent to many until recently, precisely because of the Three Rs of Risk Corridors, “free” reinsurance and future “risk adjustments,” the Affordable Care Act always created this scheme that looked like it preserved private insurance but in fact converted insurers largely into claims processors in a system in which profitability and core insurance functions were largely controlled by the federal government.
To see the relative magnitude of the Risk Corridors program, consider the bigger picture. The CBO projected most recently, for example, that subsidies to help individuals purchase insurance via tax credits and cost sharing reductions would total $26 billion in 2014 and ramp up to $108 billion by 2017. To be sure, that figure was based on the assumption, which is beginning to look very suspect, that there would be 7 million people in the Exchanges in 2014, and thus might decrease if enrollment is considerably lower. Still, since by my calculations it seems unlikely that the Risk Corridor payments will amount to more than $1 billion per year (but see footnote below), it is not as if the cost of “Obamacare” suddenly went through the roof. Maybe Risk Corridors could be considered the “straw that broke the camel’s back,” but the Affordable Care Act has always been a stretch of the federal budget and it has been a stretch that many have long found deeply troubling.
CBO projections on the cost of the Exchanges
The more serious issue surrounding Senator Rubio’s suggestion that Risk Corridors be repealed is that such an action might well be the straw that broke the insurers’ backs. Insurers do not have to participate in the Exchanges and they certainly do not have to continue to do so in 2015. I suspect that if, anything stands right now or in the future between the deeply troubling enrollment numbers and an adverse selection death spiral caused by a combination of premium escalation and insurer withdrawals from the exchange marketplace, it is insurers’ belief that Uncle Sam will take care of the insurance industry. Indeed, that’s the not-too-subtle consolatory hint that accompanied the letter sent last week by the Obama administration to state insurance commissioners. It tells regulators and insurers that, to enable the President to keep his oft-repeated campaign promise — I don’t even have to tell you which one — the healthy insureds on which Exchange insurers were banking would now be given a sometimes cheaper (and sometimes competitive) alternative. How many of these victims of the previously broken promise would have purchased insurance on the Exchanges if forced to do so is open to question. But, at the present time, every insured helps those Exchanges survive, even if only barely.
By telling insurers that, contrary to the strong hints at the end of the Obama administration letter, there will be no relief for the additional average costs now imposed on insurers, passage of Senator Rubio’s bill might lead to the implosion of the insurance Exchanges and the death of a crucial portion of the Affordable Care Act. While such a result would hardly deter many from voting in favor of the bill, those who dislike the Affordable Care Act ought to think hard not just about how much they want it to end but in what way they want it to end. Dismantling the ACA is itself going to be difficult and painful — wait until we hear the cries from the people who deeply craved the subsidized insurance they thought they were receiving or who otherwise benefited from the Act — and ultimately entails very serious and difficult policy choices about how we want to finance healthcare in the United States. Consumer driven? Single payor? If the law is to be unwound, it would be better if it were done in as deliberate and orderly way as practicable rather than as an unforeseen result of legislation that purported to deal with a narrow aspect of the ACA.
There is, it should be noted, a compromise position that will preserve something of Risk Corridors while not adding to the federal budget deficit. One could amend the Risk Corridors provision to force it to be budget neutral. This has already been done in the companion provisions of stop-loss reinsurance and risk adjustment and there is no reason that, if legislators could act in good faith, the law could not be modified to state that payments by the Secretary of HHS to insurers would be reduced pro rata to the extent necessary to make payments in under Risk Corridors equal payments out. This potential reduction in payments might, it must be acknowledged, scare insurers and contribute to the implosion of Obamacare, but it would be less likely to do so that a bill that repealed Risk Corridors altogether.
A Footnote on the cost of Risk Corridors
Footnote: I’ve been thinking some more about a back of the envelope computations in a blog entry that attempted to develop a relationship between the number of people enrolling in insurance on the Exchanges and the size of the Risk Corridor payments. As those paying the closest attention to my prior blog post will recall, I made an assumption about the spread of the distribution of insurer profits and losses. The assumption was not unreasonable, but it was also hardly infallible. What if, I have been wondering, the spread was much narrower than I suggested it might be?
I decided to run the experiment again using a standard deviation of profits and losses only 1/10 of what it had been. I thus create regimes in which the financial fates of most insurers selling policies are closely tied together. What I find is that assuming that most insurers will either make money or that most insurers will lose money has a tendency to increase the payments the government will likely have to make if enrollment is small. In this new experiment, payments peak at about $1.5 billion rather than $1 billion in the prior experiment. Bottom line: the prior blog post was basically correct — we are dealing here with very rough estimates — but if all insurers are subject to similar economic forces the Risk Corridor moneys paid by the government might grow somewhat. Still, it is not as if the cost of Risk Corridors is suddenly going to dwarf the cost of premium subsidies and cost sharing reductions already required by the ACA.
Short answer: My best order-of-magnitude estimate is between $500 million and $1 billion for the coming year of which a third to a half could be attributed to the President’s decision to honor his promise to let Americans keep their existing health insurance.
Insurers are rightfully complaining that the move by the President to fulfill a promise he made to permit Americans with “substandard” but previously grandfathered policies to keep their health insurance is going to destabilize insurance markets. There were such complaints going in to a meeting on November 15 between President Obama and selected insurance leaders and there were somewhat muted complaints coming out of the meeting. Insurers are concerned because the people who are now being given access to another market in which insurance policies may be cheaper are likely to be precisely the healthy people that insurers who wrote policies in the Exchanges assumed would be in those Exchanges. Their concerns are important because unhappy and unprofitable insurers have a tendency either to stop writing insurance or to raise rates. That hurts policyholders and it also hurts politicians who assured the public that the rates would be affordable. (The insurers are also upset because it’s a little challenging to uncancel policies on short notice, but we’ll leave that grievance for others right now.)
The instrument by which some are proposing to pacify the insurance industry for the surprise deprivation of healthy insureds is the hitherto obscure “Risk Corridors” provision baked into the Affordable Care Act (section 1342, 42 U.S.C. § 18062, for those scoring at home). It provides that the government cover up to 80% of losses an insurer incurs on an Exchange. It was always assumed — foolishly in my opinion, but assumed nonetheless — that this backstop would be costless because the government would also effectively tax up to 80% of profits via the same provision. If the insurers systematically lose money, however, because many of the people they thought would improve the Exchange pools with their good health are being given an option to separate themselves out and keep their old often-less-expensive and often-less-generous insurance policies, the Risk Corridors provision could cost the government a fair amount of money.
So, the question is, how much money is Risk Corridors likely to cost? To use the language from my prior post, how much VOOM? If it’s a relatively small amount, that would suggest that the President (and others’) proposal to honor a campaign commitment to let people who liked their health plans keep them is a better idea than if it’s a relatively large amount of previously unbudgeted money. I thought we might try a back of the envelope computation to see what’s involved.
Time to trot out some calculus. The Risk Corridors provision basically creates a mathematical function between profitability (as defined in that provision) and the size of a positive or negative transfer payment from the government to insurers writing policies in the Exchange. So, if we knew the distribution of profitability of insurers under the Exchange we would calculate the mean payment (an “expectation” for those with some statistics background) the government would make (or receive). Of course, we don’t know that distribution yet, but we can make some guesses and get some order-of-magnitude estimates.
If one assumes that the distribution of the ratio between claims and premiums has a mean value of one (i.e. that insurers on average break even), the the expected payment of the government is zero. That’s the assumption on which the Congressional Budget Office worked when it asserted that Risk Corridors would cost nothing. But what if one assumes that the distribution of the ratio between claims and premiums has a mean value of 1.1, i.e. insurers on average lose 10%. We’ll also assume for the moment that the distribution of the ratio is “log normal” and that 95% of insurers have a claims/premiums ratio of between 0.922 and 1.22. If we do the math — here’s the link to the Mathematica notebook that stands behind these computations — it turns out that the average payment of the government is about 3% of the average premium (before subsidies). If the mean of the distribution were 0.5, i.e. insurers on average have claims 50% higher than profits, and we hold everything else the same, the average payment of the government is about 34% of the average premium (again, before subsidies). So if, just for the sake of discussion, one assumed there were 2 million people in the Exchanges and that the average gross premium was $3,500, the government would end up shelling out $210 million per year to provide insurers with some relief if they lose 10% on average and would end up shelling out $2.37 billion per year to provide insurers with similar relief if they lose 50% on average.
The graphic below shows the size of the government’s Risk Corridors obligation as a function of the mean of the claims/premiums ratio under the continued assumption that the distribution is log normal and that the spread of the distribution is similar to that described above. With a little wiggle when the mean of the claims/premium ratio is close to one, the relationship is pretty linear.
Relationship between mean insurer claims/premiums and risk corridor payments
To get the total bill for the government, however, we not only have to calculate risk corridor payments in relation to a premium amount, we also have to make a guess about how many people will enroll in the Exchanges and what their premiums will be. It’s complicated because, precisely because of adverse selection, there’s likely an inverse relationship between the number of people that enroll and the mean of the claims/premiums ratio. But since all we are trying to do here is get some order of magnitude estimates — the discussion of this Act has been hurt all along by false claims of precision — we can try to make some reasonable guesses.
Suppose, for example, that the relationship between the mean of the claims/premium distribution and the number of people enrolling in the Exchanges looks something like this.
Hypothesized ratio between enrollment and mean of claims/premium distribution
What we can now do is graph the government’s overall risk corridor payments as a function of enrollment. I’m going to assume that the average premium is $4,000 per enrollee. That’s roughly the average $328 per month that Kathleen Sebelius reported for a silver plan. If people flock to the gold and platinum plans, the average could be somewhat higher. This graph is essentially the headline of this blog entry.
Hypothetical relationship between enrollment and risk corridor payments
So, what we we see is that if, for example, enrollment for this year were to be 1 million, the total risk corridor payments might be somewhat in excess of $1 billion. If enrollment were 2 million, risk corridor payments might be $500 million. One enrollment crosses 3 million, the government actually could gain money via the risk corridors program.
There are a lot of unknowns going in to the graphic above. I do not pretend that it is precise. I do not even contend that it is accurate. Nonetheless, I believe it is useful. I do believe it provides a plausible order-of-magnitude estimate of an unforseen cost of the Affordable Care Act. If you asked for my best guess, I would tell you the Risk Corridor payments will likely be between $500 million and $1 billion this coming year as I would guess enrollment in the Exchanges will come out between 1 and 2 million (assuming they ever fix healthcare.gov). This does not mean, by the way, that the cost of the President’s fix (or of the similar bills now in Congress) is the full amount of the Risk Corridor payments. Some of these risk corridor payments might have been made even without the Obamafix. That is so because enrollments in the Exchanges may always have been overestimated and may have been made considerably lower as a result of all the fallout from the debacle of the healthcare.gov website rollout.
In the end, then, I suspect that for the coming year the price tag for the President keeping his promise that “If you like your health plan, you can keep your health plan” is going to be somewhere in the $200 million to $400 million range for the coming year. That’s about a third of the overall stabilization bill. And we’ll never know for sure because we won’t know how many of those that in fact do keep their health plan would have enrolled on the Exchange. In one sense, the money cited above may be seen as a rather inexpensive price to pay to make good on an alluring promise. On the other hand, it may also be seen as yet another unforeseen or unadvertised cost of a bill to transform American healthcare. It’s easy to make feel-good campaign promises when you aren’t fully honest about the cost.
This blog is going to chronicle what I believe will be the implosion of the Affordable Care Act. I do not believe the Exchange based system of providing health insurance without medical underwriting is likely to work or that, if it does, it will not need far more massive propping up from federal taxes than is conventionally recognized. We’ll be looking at current events, the history of the Act, important court cases, and regulatory developments. Our tools will be a careful review of primary documents, some graphical and mathematical analyses, and references to important and insightful articles written by others.
Also, there is more to the Affordable Care Act than the Exchanges. There is more than the individual mandate. There is the employer mandate, the complex systems of federal reinsurance needed to backstop the Act, the reintroduction of medical underwriting under the “wellness label” and so much more. We’ll try as time permits to take a look at developments in these important areas too.
I recognize that many are writing on this topic and that it will be hard to stay a pace of such a fast moving target. But I do feel that there is a need for some hard and at least somewhat scientific look at what is going on. It will be my goal and burden to try to provide that in the months ahead.
Oh, and who am I? I’m Seth Chandler, a law professor at the University of Houston Law Center. I’ve taught insurance law, including life and health insurance law, for many years, been a co-director of the Health Law & Policy Institute, and done considerable work on the economics of insurance and its regulation. I’ve been very active using Mathematica, a system for doing mathematics by computer, and have shown how this tool can be used to analyze legal systems and many issues in insurance law such as adverse selection, moral hazard, correlated risk and a variety of issues in life, health, property and casualty insurance.
I should also add that the views expressed here are my own and do not necessarily reflect those of the University of Houston.
Exploring the likely implosion of the Affordable Care Act