I’ve written before that net premium increases for many individuals purchasing policies under the ACA will be higher than gross premium increases. I’ve gotten some emails expressing puzzlement over this conclusion. So, in this post I want to explain in some detail why this is the case.
An example
Consider five Silver policies on an Exchange. In 2015, here is a table showing their gross premiums
1. $4,161.55
2. $3,881.27
3. $4,338.10
4. $4019.11
5. $3550.64
So, the second lowest silver policy is Policy 2, which has a premium of $3,881.27. Suppose our individual can contribute $1,000 per year based on their income. If they had purchased policy 2 their tax credit would have been $2,881.27 and their net premium would have been $1,000. If our individual purchases policy 4, however, which has a gross premium of $4,019.11, their tax credit is still $2,881.27, so they will end up having a net premium of $1,137.84
Now, suppose the gross premium increases average about 6.33% but are distributed as follows among our 5 insurers.
1. 11.38%
2. -2.57%
3. 7.26%
4. 10.28%
5. 5.29%
The new gross premiums for 2016 are thus as follows:
1. $4,634.99
2. $3,781.70
3. $4,652.87
4. $4,432.30
5. $3,738.41
The new second lowest premium is Policy 2, which has a gross premium of $3,781.70. Suppose now our individual has essentially the same income such that the amount they are deemed to be able to contribute is still $1,000. This means the 2016 tax credit is $2,781.70. What if our individual wants to keep his health plan and stick with Policy 4. Maybe our individual likes the practitioners in the Policy 4 network. The new difference between the new gross premium for Policy 4 ($4,432.30) and the tax credit of $2,781.70 is $1,650.60.
Thus, although the gross premium for the policy has gone up 10.28% (bad enough) the net premium has gone up 45.06%.
So, did I concoct some bizarre set of numbers so that the ACA would look bad? I did not. The result you are seeing is baked into the ACA.
An experiment
Let’s run the following experiment. Suppose premiums are normally distributed around $4,000 with a standard deviation of $500. And suppose the gross premium increase is uncorrelated with premiums and is normally distributed around 5% with a standard deviation of 5%. Assume there are five policies at issue. We can then calculate for each of the five policies, the gross premium increase and the net premium increase in the same way we did in the example above. We run this experiment 100 times.
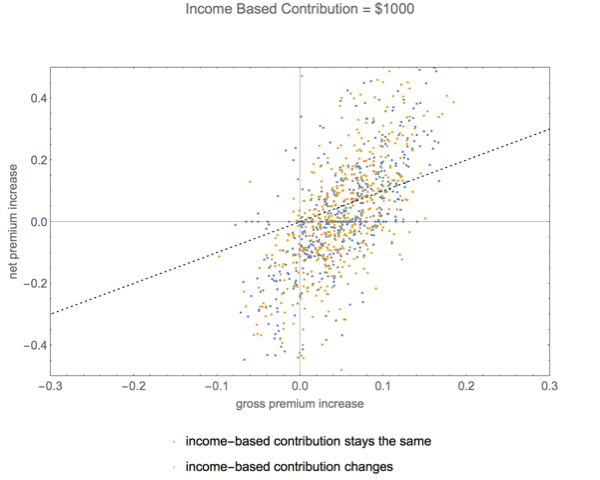
The graphic below shows the results. The horizontal x-axis shows the size of the gross premium increase (in fractions, not percent). And the vertical y-axis shows the size of the net premium increase. The dotted line shows scenarios in which the gross premium increase is the same as the net premium increase. What we can see is that for the larger gross premium increases, the net premium increases tends to be larger than the gross premium increases and for the smaller gross premium increases (or for gross premium decreases), the net premium increase tends to be smaller than the gross premium increase. Thus, about half the population will experience net premium increases larger — and sometimes way larger — than they might think from reading the news.
Is this result an artifact of, say, having our policyholder being deemed by the government to be able to contribute $1,000 based on their income? Not really. The graphic below runs the same experiment but this time assumes our individual is poorer and is thus deemed able to contribute only $500.
What we can see from the graphic is that the result is even more dramatic. The poor will see drastic divergences between gross premium increases and net premium increases. Many, for example who have gross premium increases of say just 5% experience net premium increases of over 30%.
And what of the less subsidized purchasers, those who, for example, are deemed able to contribute $3,000 towards a policy? The graphic below shows the result.
Now we can see that the gross premium increases and net premium increases are clustered pretty tightly together. Indeed, for the wealthier purchasers, net premium increases more often than not are smaller than gross premium increases. However, since most purchasers of Exchange policies tend to be those receiving large subsidies, the graphic above is not representative of the situation for most purchasers.
Did I rig the result by assuming that the income-based contribution stayed the same. No. Here’s a graphic showing gross versus net premiums first, under the assumption that income-based contributions remain the same and second, under the assumption that income-based contributions wander, sometimes going up, sometimes going down.
What you can see is there is not much difference between the yellow points — income based contribution remains the same — and the blue points — income based contribution wanders.
And, although I won’t lengthen this post with yet more graphics, the basic result generalizes to situations in which there are more than 5 Silver policies. The pattern is the same.
Conclusion
It really is true. Net premium increases will often be larger than gross premium increases, particularly for the poor. The sticker shock some received on seeing the gross premium increase figures recently released at healthcare.gov will, in many instances, be little compared to the knockout blow that will occur when people start computing their new net premiums.
One of the touted benefits of the Affordable Care Act was that, by fostering transparency, there would be greater competition in the health insurance market and that premiums would go down as a result. We now have data to help see whether competition within the various Exchanges has succeeded in reducing prices. This post, based on a scholarly talk I recently gave at the University of San Diego’s Workshop on Computation, Mathematics and Law, will suggest that the effect, if there is one, is small and subtle. It looks as if having just one seller of a product within a county may lead to somewhat higher prices, but the effect may not be robust. The methodology used here is a first cut. Whether other methodologies might tease out a larger relationship remains to be seen.
Note to ACA Death Spiral Fans: The USD conference mentioned above is one reason for the infrequent posts as of late. It’s been a busy period. Sorry. There’s A LOT to write about. Keeping track of Obamacare is at least a full time job.
Data
The data for this project comes mostly from good old healthcare.gov, which, if one forages around a bit, actually contains a user-friendly database exportable in various standard formats such as CSV and JSON describing all 78,392 plans currently being sold in 2,512 counties via the federal Exchange. Each plan is described by 128 fields, including the metal tier of the plan, the name of the issuer of the plan, the type of plan (PPO, HMO, POS, EPO), the monthly gross premiums of the standard plan for various family types, the deductibles and cost sharing arrangements of the standard plan, and the deductibles and cost sharing arrangements of the variants of the plan that feature cost sharing reductions as described in 42 U.S.C. § 18071. The remaining data comes from the United States census.
Methodology
The idea here is to consider each county of the United States as a market for health insurance and to find, for each county, the number of issuers selling plans on the Exchange, a representative measure of the price being charged by each issuer, and, therefore, a representative measure of the price charged within each county. If competition resulted in lower prices, one would expect to see — all other things being equal, which of course they are not — an inverse relationship between the number of issuers and the representative price charged within each county. We can also see, however, whether any such correlation is either spurious as a result of factors that correlate with both the number of issuers and the premiums charged or whether a stronger correlation might appear if other factors were controlled for. Here, the one other factor I took account of was county population density, the idea being that insurers might be less eager to enter counties in which the population density was low and that prices might be higher in such areas due to transportation costs.
Visualizing the Results
The “Distribution Chart” below shows a typical result from this data exploration. Here is the distribution of representative monthly premiums charged a couple in which the members are both 40 years old for a Silver PPO plan. The plot is broken down by the number of issuers within the count. If the insurer sells more than one Silver PPO plan within a county — which sometimes occurs — I take the median price for that insurer. And to determine the county price, I take the median price for all of the issuers.
Distribution Chart (basic)
The Distribution Chart works by using a dot to represent each gross monthly premium broken down by number of issuers. It applies different background colors that depend on the number of issuers within the county and shades each part of the background according to the density of premiums at that price level. Darker shades represent higher density.
We can run the same analysis for different purchasers, different metal levels, different types of plans and using different measures to move from issuer prices within a county to a single representative issuer price and to move from representative issuer prices to a representative county price. Here, for example, is the Distribution Chart for gold PPO plans purchased by couples age 40 with two children in which I use the minimum price offered by the issuer within each county and then use the 25th percentile price of those minimum prices to come up with a representative county price.
Distribution Chart for Gold PPOs (Coupled +2 children, Age 40), minimum by issuer, 25th quantile to derive county price
We can also aggregate matters. Here is the Distribution Chart for all Bronze plans of all types (HMO, PPO, POS, EPO) in which I take the median of multiple plans issued by a single issuer and then take the median value of all issuers to derive a county price. I do this for a single adult, age 30.
All bronze plans
Here’s an analysis examining all types of Bronze plans but using a variant of the visualization. The individual dots are suppressed and we now have little histograms for situations in which there is 1 issuer through 8 issuers.
Histogram density visualization of all bronze plans
Eyeball Analysis
When I eyeball this data and many more permutations that I have produced, I at least do not see any dramatic and widespread relationship between the number of issuers within a county and the representative gross premium being charged. For some combination of parameters, one occasionally sees higher prices when there is only one issuer in the county, but generally the picture, at least the naked eye is quite blurry. The one thing I can say with some certainty is that the family-type of the purchaser — individual, couple, family with children — does not appear to affect matters. Premiums appear quite uniformly scaled across these groups.
What I do consistently is, as noted here and here, that there are many counties in which there is only one issuer of a particular level and type of plan. For Silver PPO plans, for example, in which one wants a medium level of cost sharing but wants at least some freedom in selecting a provider, of the 2,512 counties, 20% of the counties have no issuers with such a plan while another 36.6% have only one such issuer. Only 13% of the counties have three or more issuers of these plans. The pie chart below shows the distribution of issuers.
Distribution of Silver PPO issuers
Or, suppose one simply wants a bronze plan of any sort. What we see is that 16.2% of the counties apparently have no such plan, 27.9% have only one issuer and 31% have 2. Thus, only about one third of the counties have 3 or more choices for a simple bronze plan. The pie chart below shows the result.
Distribution of bronze issuers
Statistical Analysis
Sometimes the human eye and the human brain, magnificent as those organs are, do not see patterns that in fact emerge when studied through the lens of statistics or machine learning. Modern computers and statistical activities make it easy to go beyond eyeballing data. What I have done, therefore is to merge representative premium data with data on the population density of each county and see if any statistically significant relationship emerges between the number of issuers within each county and the county representative price.
I want to start with the simplest model: a linear relationship between the number of issuers and the county representative premium. I will do the analysis at first for my baseline Silver PPO purchased by a couple age 40 where I use the median price of the issuer if they sell more than one Silver PPO within the county and the median price of issuers . The graphic below shows the results. There is a statistically significant relationship between the number of issuers and the premium. For each additional issuer, the gross premium goes down by about $16. The model overall, however, accounts for only 2.1% of the variation in representative county prices, meaning, roughly speaking, that 98% of the variation in premiums is correlated with factors other than the number of issuers.
Linear regression of county representative price on number of issuers
The problem with leaping from this finding to an attempted vindication of claims about the virtues of the ACA is that the result, even weak as it is, depends a bit on specification of the model. This gets a little technical, but unless one assumes a priori that there is some good reason to think that the relationship between number of issuers and price is in fact a linear one, restricting the regression to a simple linear model is potentially misleading. Here, for example, I regress the same data on n (the number of issuers), n-squared and the log of n. All of the coefficients in front of the various terms are still significant, but if one looks at the picture one gets a much more complex story. It appears that having one issuer does lead to high prices and that having two issuers may minimize the number of prices. As one increases the number of prices beyond two prices go up again until we peak at four issuers. This model explains almost 9% of the variance in pricing, which is considerably better than the simplest linear model but still not very good. Clearly, pricing is determined by much more than the number of issuers within a county.
Pricing model based on linear, quadratic and logarithmic term
The observed pattern when this more complex regression model is used appears roughly to persist for all metal types of HMOs and PPOs except platinum PPOs where we see the price increase as the number of issuers within a county increases. The family type of the purchaser appears not to affect the general shape of the relationship. I am never able to explain more than about 12% of the variance in premium pricing when I use just the number of issuers within the county as my single explanatory variable.
I have some sense that the population density of a county might have an effect on pricing. Perhaps lower density counties are more expensive. Or, it could be the case that higher density counties, which may have fancier equipment, are more expensive. The regression below shows a simple linear regression using two variables: number of issuers within the county and population density of the county. As one can see, the results are little changed. Both variables have effects that are statistically significant but small. As one goes from 1 to 2 issuers, the price drops by about $17 per month. As one goes from a county in which the population density is 4.3 (which would put it in the 10th percentile) to a county in which the population density is 491 (which would put it in the 90th percentile), the price goes up by $7 per month. The model still does not explain much (adjusted R-squared <0.03). Here are the results in more detail.
Linear regression using number of issuers in county and population density
Again, I can use a more complex specification. Below I show the results of using linear, quadratic and logarithmic terms for both number of issuers and population density. What we see is a complex picture in which having just one issuer appears to persist in causing somewhat higher prices and in which population density plays a small role. But we are still able to explain less than 10% in the variation of premiums. Again, whatever is going on in premium pricing models, is a lot more complex.
Linear, quadratic and logarithmic terms for number of issuers and population density
A Foray into Machine Learning
I also attempted to see whether a computer could find a formula that predicted county representative gross premiums any better than my statistical models when given free rein to do so. To do this, I loaded the data into a program called Eureqa from Nutonian .com, which basically uses “genetic programming” to find models that predict well. The basic idea is to treat mathematical formulae kind of like strands of genetic material and permit mathematical formulae that perform better to evolve via mutation and “sex” to produce what may be yet formulae. Sometimes it produces amazing results and — well — sometimes it does not. Either way, however, genetic programming and other methods of machine learning are a useful complement to traditional techniques. They help one check whether the apparent incapacity of traditional methods such as regression are an artifact of limited specifications or the result of unavoidable noise in the data.
In this case, Eureka basically found little. It found some functional forms a human might not come up with such as the one below, which appeared to predict decently, but in fact did not do any better than the models I developed by hand. The foray into machine learning suggests, then, that the limited ability of our our statistical models to predict well is not the result of a failure to specify the model correctly but rather the result of noise in the data and unobserved variables.
Thoughts
Unfortunately, perhaps, the results shown here are not the sort one writes home about or that get on the front page of either scholarly publications or news reports. They are kind of “meh” results. Maybe market concentration has an effect, but, at least as revealed by the data here it is small. So, why might this be?
1. Perhaps the number of insurers in the Exchange is not as relevant anymore as might be thought. Given the availability of individual policies off the Exchange in some states, the number of individual polices within the Exchange may not be as important. I don’t have the data on off-Exchange policies and neither, so far as I know, does anyone else.
2. Maybe pricing is determined more by the identity of the insurer than the number of insurers. Suppose, for example — and I do not say this is true — that Blue Cross made different assumptions about adverse selection and moral hazard with the purchasing population than did, say, United Healthcare. Markets that Blue Cross entered aggressively might thus have lower representative county prices than markets in which they did not. Or suppose that Blue Cross was able to use market power and/or superior skill to create narrower networks that nonetheless satisfied regulators. This might account for markets in which Blue Cross was present exhibiting lower prices. Or suppose that Humana was more willing to take a loss the first year in order to supposedly lock in business than was Blue Cross. This too might explain lower pricing. This suggests another experiment in which one looks at pricing as a contest and seeing how each of the competitors fared against each other.
3. Maybe consumers are very sophisticated such that “Silver PPO plans” are not comparable. If consumers, for example, value the precise package of benefits and providers offered by, say, Blue Cross in a county as being quite different from the precise package of benefits and providers offered by, say, Humana, then we can’t just count issuers in determining the level of competition in a county.
4. Population density isn’t the right variable to include. Maybe what we need is some measure of medical pricing by counties. Or maybe, as the Wall Street Journal suggested, we need to include some measure of income or income inequality. Sadly, it may be that healthcare costs more in poorer counties, perhaps because the poor have more serious health problems. At the moment I have not included those variables. Future examinations of this area should probably do so insofar as the data permits.
Note
Ordinarily, it would be my practice to make the Mathematica notebooks used to conduct this analysis fully available. I very much believe in transparency. Unfortunately, this analysis was conducted using features in a beta version of Mathematica 10 and I have signed a non-disclosure agreement with respect to that software. While I received consent to show certain results from use of that software, I did not request or receive consent to show code. Moreover, the code would not work on computers that do not have Mathematica 10. I commit to releasing the code as soon as Mathematica 10 is out of beta. I don’t think my NDA stops me from saying, however, that Mathematica 10 looks somewhere between absolutely spectacular and completely mind-blowing.
Those optimistic about the success of the Affordable Care Act have been noting over the past several months that the premiums offered by insurers have been lower than those earlier forecast. But if one looks carefully at the original rhetoric, the comparison tends to be between some of the lowest premiums offered within a jurisdiction and those originally forecast. And this metric, according to ACA proponents, is appropriate because they expect consumers to focus purchases on the lowest cost policies.
But what if the lowest premiums are lower than expected not because the mix of purchasers is thought to be fine or because of cost cutting measures enabled by the ACA, but simply because all this metric exposes is the work of the insurers who priced their policies below actual risk? The “winner’s curse” is the term economists and game theorists give to situations in which, in an atmosphere of uncertainty, people bid on an item in an auction environment. What will often happen is that the “winning” bidder will tend to be one that loses money.
It is quite possible that all we are seeing with “low” ACA pricing, as measured by ACA proponents, is “the winner’s curse” in action. We may well be looking at insurers who (a) got it wrong or (b) thought the government would most greatly subsidize their losses or (c) for strategic reasons, decided to sell a “loss leader” in the first year or so of the ACA in order to lock consumers into their networks and their doctors with the idea that they could substantially raise premiums in the future. If this hypothesis is correct, individual policies under the Exchange are a lot less stable than many ACA proponents are asserting.
To summarize the results of the computations shown below, if the mean premium charged by insurers selling a type of policy (Silver HMO Plans, for example ) in a given geographic region (Harris County, Texas, for example) reflects the true risk posed by ACA policy purchasers, about 20% of the low bidders — the ones that I suspect will get a disproportionate share of the business — stand to lose at least 20% on their policies before the Risk Corridor program bails them out.
The big story as the ACA unfolds may be that some insurers — the ones who ended up with the business — simply made an error of exuberance in a new market and priced their policies too low. While these insurers will, thanks to a federal subsidization program for losing insurers called Risk Corridors, not entirely lose their shirts in the first year of the program as a result, they do stand to lose a lot of money that they will likely want to make up in any subsequent years of the Affordable Care Act.
New data analysis finds significant dispersion in plan premiums
This post will contribute some new data analysis that suggests the likelihood of the winner’s curse materializing as well as the magnitude of such a curse. Basically, I have sucked into my computer official government data on the 78,000 plans sold on the federal marketplace and done a lot of number crunching. The data shows a significant dispersion of prices offered by insurers for plans in the same geographic area, of the same metal tier and offering the same form of coverage (PPO, POS, HMO, or EPO) . While this dispersion does not prove that the low prices are outliers reflecting either miscalculation by some insurers or only-temporary use of low prices, it does suggest a significant possibility that such is the case.
Let’s take an example. Here are the prices offered where I live, Harris County, Texas — mostly Houston — for an HMO Silver Policy to a couple with two kids. The couple has an average age of 50 years old. We’ll call this hypothetical family “The Chandlers,” as a matter of convenience. The graphic shows the dispersion of premiums normalized so that the lowest price for a given policy is given a value of 1.
Dispersion plot for Harris County, Texas, Silver HMO policies sold to Couple, aged, 50 with two children
As one can see, for the Harris County, Texas policies shown here, although there are three policies that have premiums fairly close to the minimum, there are, however, two policies that have premiums more than 30% more than the minimum. If the mean premium estimated by insurers is “correct,” the insurer selling a Silver HMO policy at the lowest price will lose about 17%. The implication, if the Harris County plan is representative and if the mean premium is closer to the true risk than the low premium, is that the insurers most likely to win business due to low prices are likely to lose a considerable amount of money.
There are several potential rejoinders to the suggested implication of the graphic. Let me address each of them in turn.
Might Harris County, Texas be unusual?
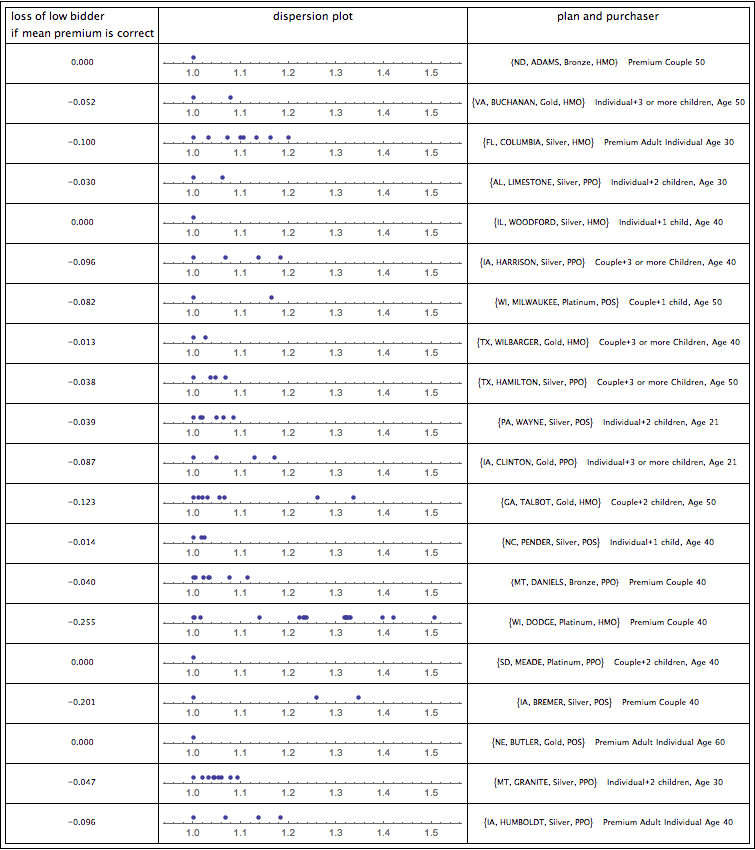
One response is that the example for Harris County, Texas Chandlers is unrepresentative. Houston, for example, has some very fancy hospitals and some not so fancy hospitals; so maybe premium dispersion for Harris County simply reflects whether one has access to the fancier hospitals (and the doctors who have admitting privileges to them). I have considered this possibility and find that, actually, the example I provide is pretty representative. Here, for example, are 20 randomly selected examples. For each plan, I show the amount the low bidder would lose if the average premium is “correct,” the dispersion of premiums, and the plan and purchaser randomly chosen. Of the ones in which there are any significant number of policies available, most of the premiums show a dispersion pattern qualitatively similar to that in Harris County for The Chandlers. Indeed, some of the random examples show dispersion considerably greater than that for the Harris County silver HMO policies. Except where there is little competition for plans and the low bidder is thus selling at the average price, the result presented above does not look like a fluke.
Dispersion Plot and potential losses of low bidder for 20 random plans and purchasers
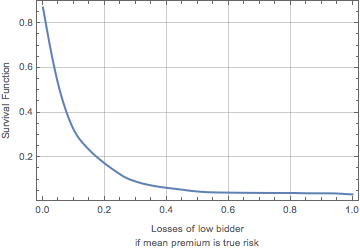
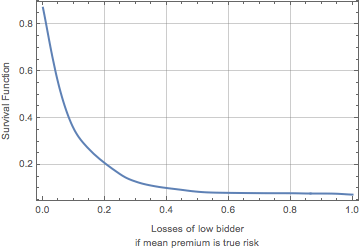
I can double check this result by computing for 5,000 random combinations of plans and purchasers the losses of the low bidder if the true risk was equal to the mean premium charged for policies and purchasers of that type. The graphic below shows the “survival function” (or “exceedance curve”) for the resulting distribution of these losses. The value on the y-axis is the probability that the losses will exceed the value on the x-axis. The results shown below confirm that the situation for Harris County Silver HMO plans sold to The Chandlers is not all that unusual. As one can see, losses of more than 10% take place more than 30% of the time and losses of more than 20% take place about 17% of the time. A rather scary picture.
Exceedance curve of the distribution of losses of low bidders for random plan-purchaser combinations on the assumption that the mean premium represents the true risk
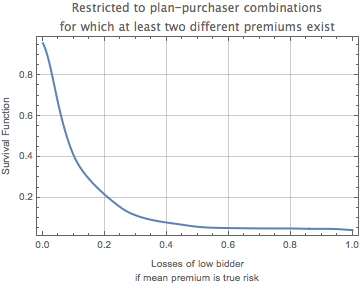
In fact, however, the situation may be even worse than depicted in the graphic above. Sometimes the losses computed by this method are low because the low bidder is also the only bidder. If we consider situations in which there is more than one bidder, here is the resulting survival function (exceedance curve) of the distribution. As one can see in the graphic below, the distribution of risks is shifted slightly to the right. Now 40% of the low bidders stand to lose at least 10% and about 21% stand to lose at least 20%.
Exceedance curve of the distribution of losses of low bidders for random plan-purchaser combinations where at least two premiums exist on the assumption that the mean premium represents the true risk
Maybe the higher priced policies are better?
Another potential explanation for price dispersion is that, even if the policies are priced differently, that does not mean that the cheapest policies are selling for too low a price. All Silver HMO policies sold in Harris County, Texas to The Chandlers may not be the same. Some may have different deductibles or different networks.
The first response to this rejoinder is that the actuarial value of the policy — the relationship between expected payments by the insurer and premiums — should be about the same for each metal tier of policies. Silver policies should all have actuarial values, for example, of 70%. So it should not be the case that one silver policy has cost sharing different than the cost sharing of another silver policy in a way that would affect the premium charged for the policy. Moreover, the calculations underlying this post keep HMOs, PPOs, POS plans and EPOs apart; so it should not be the case that observed premiums differ because, perhaps, the cheaper plans are HMOs whereas the more expensive ones are PPOs.
Of course, cost sharing is not the only way in which policies within a given location, of the same metal tier and sold to the same purchaser could vary. One policy might offer richer benefits than another. It could have a richer network with more doctors available or more prestigious and expensive hospitals inside the network. Could that be responsible for a substantial part of the premium dispersion we see? It’s impossible to tell for sure — the data published by HHS does not attempt to quantify the richness of the network being offered. I do find it difficult to believe, however, that such differences are responsible for the entirety of differences in excess of 20% between the low bidder and the mean bid, or, for that matter, differences in excess of 40% that sometimes occur between the low bidder and the higher bidders.
Maybe the average premium is meaningless; the low bidder got it right
Of all the potential rejoinders I have considered, the one now forthcoming is the one that is most troubling. There is nothing the data standing by itself can tell us whether most of the insurers have it right and the low insurers are about to lose their shirts or whether the low insurers have been more insightful or have managed to keep costs down such that they will break even (or even make money) selling their policies at low premiums. And, yet, I am doubtful. One can view the mean or median of the premiums as an “ensemble model” of the true cost of providing care under the Affordable Care Act. And there is research (examples here, here and here) suggesting that ensemble models predict better in many open-textured situations than individual models. So, while it’s possible, I suppose, that in every jurisdiction the low bidder is predicting more accurately than the group of insurance companies as a whole, such a result would be surprising. A far simpler explanation is that the low bidder — the one who is likely to win business from price sensitive insureds — is succumbing to “the winner’s curse.”
Maybe the disaggregation of plans is misleading
This is a very technical objection, but consider carefully what I have done. I have looked at all policies of a given metal tier and a given plan type in a given geographic location sold to a certain family type such as “all silver policies in Harris County, Texas, sold to The Chandlers.” But, really, plans are sold not to just to The Chandlers but to all family types. So, it could conceivably be that while the plans sold to the family type I am looking at are highly dispersed, the average premiums over all family types (weighted by prevalence of the family type) are far less dispersed. This strikes me as unlikely — why would an insurer be overcharging one family type relative to another — but you can not rule it out a priori. Maybe — just maybe — the dispersion we are observing is not real; it is just an artifact of my disaggregation of the data.
I would, of course, love to aggregate the data and see if the high degree of dispersion persists. The difficulty with this cure comes with the problem of weighting the data. We don’t know the distribution of policies sold among family types. We don’t know, for example, whether The Chandlers constitute 2% of policies sold or 5% of policies sold. So, I can’t perform a perfect aggregation of the data. One way to get a feel for the objection, however, is to simply take an unweighted average of the premiums for all the family types identified in the database and aggregate it that way. This is far from perfect, and we could spend a lot of time refining it, but it should provide a clue as to whether the disaggregation of plans is significantly responsible for the high degree of observed dispersion.
The graphic below shows the exceedance curve for losses of the low bidder assuming the mean premium is the true risk based on an unweighted average of family types purchasing the policies. One can see that 20% of the low bidders will lose at least 20% if it turns out that the mean premium charged for similar policies reflected the true risk. Upwards of 35% will lose more than 10%. A quick comparison of this curve with those above shows that it is essentially the same. There is nothing that I can see suggesting that the fundamental result shown in this blog entry — high dispersion of premiums among what should be similar policies and the potential for significant losses by low bidders — is an artifact of the methodology I have employed.
Exceedance curve for losses of low bidder assuming mean premium is true risk for aggregated purchaser types
Conclusion
In the end, even the extensive data that the government is put out is insufficient to determine definitively whether the lower priced insurers in the individual Exchanges are about to lose money. There are more optimistic interpretations of the observed premium dispersions: maybe it is the low bidders who are “getting it right” or maybe the low bidders have just found ways to keep costs down through better negotiating or cheaper care networks. But if these optimistic explanations prove insufficient, what this post shows is that while some insurers will likely do just fine there are a substantial minority of insurers who are about to get bitten by the “winner’s curse” and get a large volume of purchasers for whom the premiums charged will be insufficient to defray the expenses incurred.
Technical Notes
The data used here was taken directly from the United States Department of Health and Human Services. It was analyzed using Mathematica software, which was also used to produce the graphics shown here.
Much has been made here and elsewhere about how young people are subsidizing older people under the Affordable Care Act. While there is a substantial element of truth to this contention, at least young people generally get to become older people. So, if the ACA were to last for decades, one could drive a small bit of comfort by viewing the arguable inequity as instead amounting to younger purchasers under the ACA just financing the health care they will receive at subsidized rates as they enter their 50s and beyond. The analogy doesn’t work terribly well because unlike something like a long term life insurance policy in which a similar “subsidy” exists, there is nothing that forces those insured later in life to have insured earlier on. But at least youth is a “burden” that most of us share.
A closer look at the evidence, however, shows that the major determinant of whether someone is subsidizing another or being subsidized under the ACA is gender. As shown here, gender is more important than age for purposes of ACA subsidization. And, for most of their adult lives males subsidize women under the ACA. Since gender is largely immutable, males never get the money back. While there are many factors that bear on whether this system is fair, the extent of subsidization is large enough to be worth considering.
Subsidization by gender and age
The graphic above shows the extent of subsidization. For each adult age (21-64) and each gender, I show the subsidy (positive or negative) the person receives under the ACA. The pink line shows the subsidy for women; the blue line shows the subsidy for men. Subsidization is the difference between the expected costs the person incurs and the person’s premiums under the ACA (without consideration of any government premium subsidies) normalized by dividing the difference by the person’s premiums. Expected costs are calculated based on research by the Society of Actuaries and available in Excel data format from this web site. Premiums are calculated based on data provided by the Kaiser Family Foundation following its study of the ACA. To make sure that the units of of cost used by Kaiser and the Society of Actuaries match up, I apply a multiplicative correction factor to the premiums to ensure that the total level of subsidization is zero assuming that the estimated distribution of uninsured all enroll in ACA plans at an age-independent rate. Use of more complicated assumptions about enrollment patterns, such as incorporation of the apparent fact that most of those purchasing policies in the individual Exchanges already had insurance, would result in a different correction factor but should not alter the basic conclusions of this post about cross-gender subsidization.
When one adds children into the mix, the picture becomes a bit more complex. As shown in the graphic below, insurers under the ACA appear heavily to subsidize children of both genders, although male children are subsidized somewhat more. The calculations here are based on an assumption that child-only policies cost 65.2% of the price for policies sold to 21 year olds. (The 3:1 constraint on the ratio of premiums under the ACA applies only to adults (42 U.S.C. § 300gg(a)(1)(A)(iii)). This assumption was based on my sampling actual policies sold in the individual Exchanges under the ACA.
Subsidization by gender and age for all ages
What is curious and perhaps somewhat comforting to those wanting to see the ACA succeed is the fact that, notwithstanding the significant differences in subsidization, women have not enrolled at rates way higher than men. Overall, government statistics show that 54% of the enrollees are women and only 46% are men. Nor are children forming a large part of the group enrolling in the individual Exchanges notwithstanding the high subsidization rates; they amount to just 6% of the total enrollees as of January 1, 2014. Now, part of this relative equality in enrollment rates by gender could be due to the masking effects of aggregation. It might be that the female/male ratio is considerably higher among those ages 25-35, where the subsidization differential is quite large and the female/male ratio is much lower among those over age 60. Thus, even if the overall ratio of enrollees was quite even, we could conceivably be seeing unequal enrollment patterns within age brackets. As noted in an earlier post, neither the federal government nor any of the states have released data with the degree of detail that would be needed to confirm or refute this possibility and thus the actual joint distribution of enrollment by age and gender remains a matter for estimation using algebra and numeric methods rather than actual data. Still, it certainly appears that the rate of subsidization can not be the only factor affecting enrollment patterns; matters such as income, savings, risk aversion, as well as political, cultural and social factors are likely to be playing a role as well. How else can one, after all, explain the enormous differences in rates of enrollment across various states?
Now, is this “fair”? That’s a difficult question. Most serious questions about insurance underwriting justice are difficult. (I’m going to include a short bibliography at the end of this post). A large chunk of the difference between male and female healthcare expenses are based on the attribution of costs arising out of joint sexual activity to the female only. It is, after all, the female’s body that is primarily affected by pregnancy. That attribution is based mostly on convenience, however, and, in many cases, the difficulty that would be created in trying to collect from a biological father. Moreover, it may be that subsidization in this area is compensatory, addressing countervailing subsidies of men in other government programs.
Even if it is fair, however, to the extent potential enrollees are responding to the extent of subsidization, we need to be concerned that unisex rating is reducing the efficacy of the ACA in shrinking the number of uninsureds. Remember all the ills created by lack of insurance that substantially motivated the ACA? Charging men “too much” leaves many of those ills untreated. If men are not signing up because they are being asked to pay too high a price, the goals of the ACA in reducing the number of uninsureds and improving individual health are compromised. Let us not forget as various politicians attempt to diminish expectations about the achievements of the ACA that it was heavily advertised as a program to reduce the number of uninsureds. Don’t believe me? Look here (32 million), here (34 million by 2019) and here for examples.
There are two additional pictures that may be helpful to those graphically minded in considering this issue. The first, shown below, shows the expected costs of males (blue) by age, the expected costs of females (pink) by age, and the unisex ACA premium (green)(normalized so that the overall subsidization rate would be zero if enrollment rates were age-independent).
Comparison of expected costs by gender and unisex premium
The second graphic lets one compare the degree of age subsidization under the ACA. The purple line (kind of a blend of blue and pink) shows the expected costs of enrollees assuming that 50% are male and 50% are female. The green line shows the unisex ACA premium, again normalized so that the overall subsidization rate would be zero if enrollment rates were age-independent among the previously uninsured population. (A different normalization metric should not dramatically change the picture). As one can see although there is a zone between ages 20 and 32 in which premiums are exceeding cost and a zone between ages 60 and 64 where costs are exceeding premiums, and, although as mentioned above, children are heavily subsidized, for most of adulthood, premiums track expected costs pretty closely. This may help explain why neither under my analysis nor under that of the Kaiser Family Foundation do departures of the age distribution from those originally foreseen have a gigantic affect on the profitability of the system. What might have a larger effect, if it were to occur, would be departures of the gender distribution of enrollees from those originally foreseen; but, as mentioned above, thus far this does not seem to be occurring.
Comparison of blended expected costs and ACA premiums
I do need to add one critical note. All of this assumes that the expected costs for each age come in as predicted. This is hardly known for sure. There are many reasons, including adverse selection, moral hazard, and others why those costs might depart seriously from that which was projected.
A “starter set” bibliography on insurance underwriting justice
Kenneth S. Abraham, Distributing Risk (1986) (the starting point for thinking about this issue)
Tom Baker, Containing the Promise of Insurance: Adverse Selection and Risk Classification, 9 Conn. Ins. L.J. 371 (2002-2003), available online here.
Seth J. Chandler, Insurance Underwriting with Two Dimensional Justice, available here.
Seth J. Chandler, Insurance Regulation, in the Encyclopedia of Law and Economics, available here.
City of Los Angeles Department of Water & Power v. Manhart, 435 U.S. 702 (1978) (available here)
Technical Note
The Mathematica notebook that underlies the analysis and graphics presented in this blog entry is available on Dropbox here.
Earlier this month, the Department of Health and Human Services released more detailed information than it had before on the age distribution and gender distribution of enrollees in the individual markets serviced by the various Exchanges. What it did not do, however, and what needs to be done in order to better predict the likelihood of significant insurer losses in the Exchanges and, thus, greater pressure on premiums is to release data on the combined age and gender distribution of the enrollees. We don’t know, for example, how many woman aged 35-44 are enrolled in the Exchanges. This finer look at the data is important because, as discussed in a previous post, it is the combination of age and gender that bears a stronger statistical relationship to expected medical expenses. And, while the ACA incompletely compensates for age in its premium rating scheme through dampened age rating, it does not compensate at all for gender.
With the help of Mathematica, I have combined some algebra and some numeric methods to try and reverse engineer out combined distributions of age and enrollment that meet various constraints. I believe I have succeeded in finding a plausible combined distribution that can be used in developing plausible models of the likely extent of adverse selection in the individual health insurance markets under the ACA. I present the result in the table below and the chart below. I then have a “how it was done” technical appendix. My work involves creation of a high dimensional polytope that satisfies the existing data and then a search for points on that polytope that appear most plausible. I have also posted a Mathematica notebook on Dropbox that shows the computation.
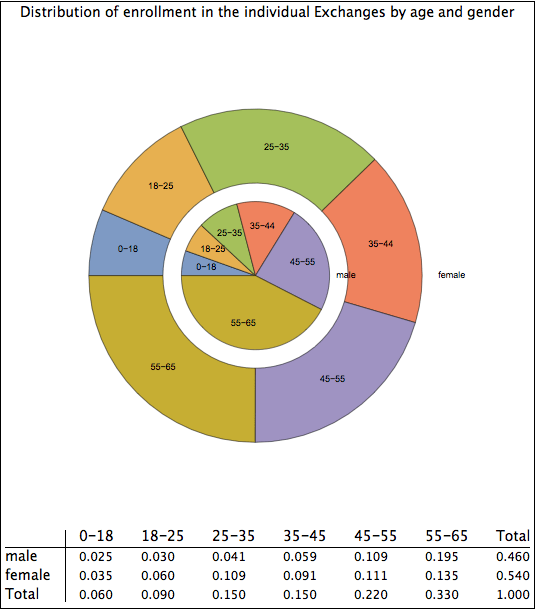
Plausible age/gender distribution of ACA enrollees
The pie chart above first groups the enrollees by gender. The inner ring shows males and the outer ring shows females. It then groups the enrollees by age bracket. As one can see, women outnumber men significantly in the 18-45 group, are about equal among minors and those between age 45 to 55, and are outnumbered by men in the 55-65 age group.
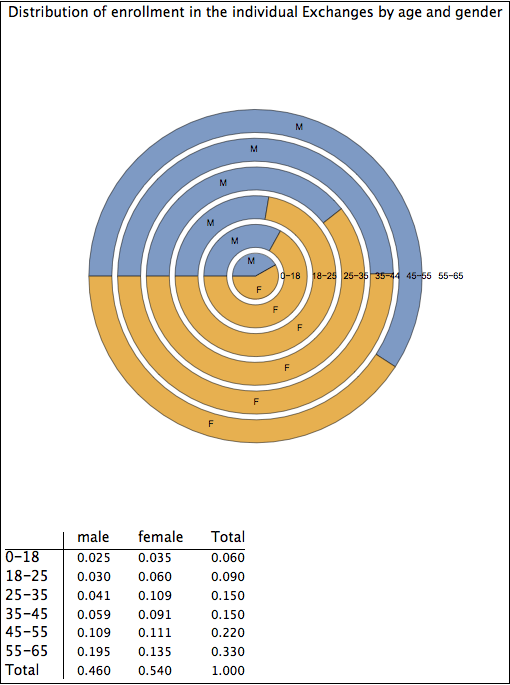
The graphic below shows the same data, but now age is the first grouping mechanism.
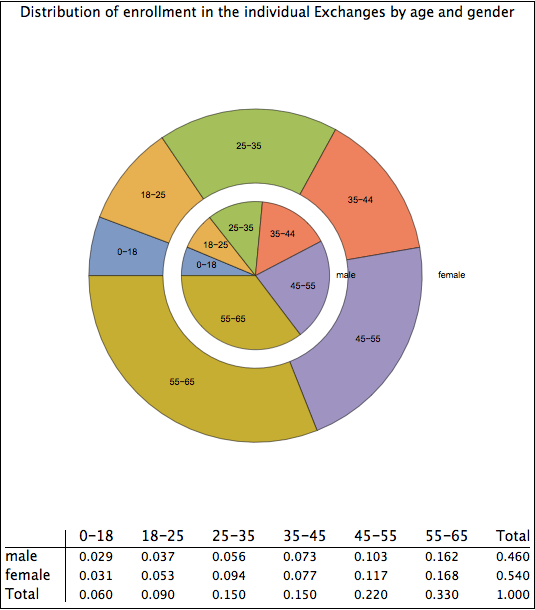
I also attempted to find the combined distribution that would satisfy the observed marginal distributions of age and gender but that would greatly reduce adverse selection. The graphic below thus presents pretty much of a “best case” for the combined age-gender distribution in the Exchanges. Notice that now it is only in the 18-35 year old age brackets that there are substantial variations in the rates of male and female enrollment. I very much doubt that the actual statistics are as promising for ACA success as depicted in the graphic below, but I present them here to show the sensitivity of my methodology to various assumptions.
Distribution of enrollees by age and gender that would substantially reduce adverse selection
The next step
The next step in this process is to try to compute the difference between premiums and expenses based on these combined age-gender distributions. I will then compare it to the difference between premiums and expenses based on an age-gender distribution that might have been expected by those who earlier modeled the effects of the ACA. The result should provide some insight into the magnitude of combined age-based and gender-based adverse selection. It should be similar in spirit to the work I showed earlier on this blog here. I hope to have that analysis posted later this week or, I suppose more realistically given my ever pressing day job, early next week.
How it was done
I have essentially 12 variables we are trying to compute: the number of enrollees in the combination of two genders and six age brackets. I know 9 facts about the distribution based on data released by HHS. I know the total number of males and females and I know the total number of persons in each age bracket. And I have 12 constraints on the values: they must all be positive. Using Mathematica’s “Reduce” command, I can use linear algebra to find the polytope that satisfies these equations and inequalities. I get an ugly expression, but it is one Mathematica can work with.
I can then sample 12-dimensions points on the polytope using Mathematica’s “FindInstance” command. I found 2400 points. Each of these points represents an allocation of enrollees among age and gender that satisfies the known constraints. I can then score each point based on its “distance” from my intuition about the strength of adverse selection. That intuition is expressed by “guesstimating” likely ratios between males and females for each of the six age groups. I use a “p-Norm” and Mathematica’s “Norm” command to measure the distance between the six male/female ratios generated by each of the 2400 points and my intuition. I then take the 10 best 12-dimension points and thus obtain a 10x2x6 array. I take the average value of each of the 12 values over all 10 sample points. It is that average that I show in the first two graphics above.
I then permitted the strength of adverse selection to vary by exponentiating the ratios in my intuition. By setting the exponent to zero, I basically try to minimize gender-based adverse selection and keep the gender ratios as close to each other as possible. The results of this effort are shown in the final graphic.
The Department of Health and Human Services released updated data today on enrollment on the Exchanges including, for the first time, greater breakdowns on enrollment by several key categories: age, gender, and the metal level of purchase. The result of this long awaited and much requested data is, at first glance, very much a mixed picture. Some of the overall statistics do not look as problematic as some — including me — had feared they might be. But it looks as if there is a very serious potential for large adverse selection problems brewing in a number of states, most notably West Virginia, Mississippi, Maryland and Washington State.
The good news for the ACA from the data
There are three major pieces of good news for those who support the goals of the ACA.
1. The overall gender distribution of enrollees, 54% female, 46% male does not appear on preliminary inspection to be sounding “red alert.” To be sure, the problem may be a little greater than would otherwise be suggested by the aggregated numbers if the middle age group is more heavily female and the oldest group of enrollees more heavily male that the aggregated numbers suggest. And Mississippi is troubling with 61% female enrollment (and for other reasons, see below). But, overall, and if they hold up, these do not appear to be the the kind of numbers that would be way beyond what insurers likely expected or that, standing by themselves, would be devastating to an insurer on an Exchange.
2. Several states have total enrollments and the age distributions that should reduce the possibility of a serious death spiral getting started. New York and California are the two big states doing better than most. Connecticut is doing very well also.
3. The metal tier distribution is 80% for Bronze and Silver policies and only 20% in Gold and Platinum. That’s comforting for adverse selection. A higher proportion of enrollment in the more generous plans would have been a warning sign that enrollment was coming disproportionately from the sick. There’s a footnote on this point later on — we are not out of the woods — but this is definitely better news for the ACA than a distribution of, say, only 50% Bronze and Silver purchases.
The bad news
Just because the ACA is doing better than some had forecast on an overall basis does not mean there will not be very serious problems in some states. Given that the statute is presently unamendable as a practical matter, problems in just a few states can hurt a lot of people. The data released by HHS today shows that there are a number of states in serious trouble.
The table below shows current enrollment in states that appear at first glance to be in significant trouble. (There may be states that are as bad as those shown in the table below; I kind of eyeballed the data, which was not provided in a nice electronic format, to select what appeared to be a problem). I also show the projected number of purchasers, the percentage of current enrollees as a fraction of purchasers, the percentage of “young invincibles” as a fraction of the enrolled population and the percentage of the expensive 45-64 year old age group.
I also construct a “back-of-the-envelope”/quick and dirty “Maelstrom Index” that roughly measures the problems confronting the individual Exchanges in the state. The maelstrom index is calibrated to run from 0 to 1 with a 0 score meaning the state is in excellent shape and a 1 meaning there is an extremely high risk of an adverse selection death spiral materializing. It is not a probability measure. The formula for the maelstrom index is shown at the end of this post.
As one can see, there are a number of states that have serious potential problems. West Virginia is problematic with 66% of its enrollees ages 45 to 64 and only 17% ages 18-34. Almost all experts would concede that this poses serious risk of adverse selection. And the overall fraction of enrollment relative to projections, just 20%, suggests that West Virginia’s insurance pool may be disproportionately populated by the sick. Mississippi is likewise a problem with enrollment only 14% of that projected, 58% in the age 45-64 bracket and, as mentioned above, 61% female enrollment. I have to believe that insurers writing in Mississippi are deeply concerned about these numbers.
Also troubling are the numbers in Texas, Washington State, and Ohio simply because, as an absolute number, there is such a large absolute difference between the number of people projected to purchase and actual enrollment. I’ll speak more about all of these numbers and try to update the chart in the days ahead.
The unknown
There’s one key piece of data not found in the HHS release today. The number of “enrollees” who have actually purchased policies. If this conversion rate is, as I fear, hardly 100%, the numbers presented today overstate the extent of purchases in the Exchanges and understate the dangers of adverse selection breaking out in many states.
On December 17, 2013, the Kaiser Family Foundation published an influential study that comforted many supporters of the Affordable Care Act who had been made nervous by early reports that the proportion of younger persons enrolling in Exchanges was significantly less than expected. If true, such a disproportion could have created major stress on future premiums in the Exchanges because the private Exchange system under the ACA depends — or so it was thought — on younger persons subsidizing older persons. The Kaiser study asserted, however, that even if one cut the number of younger persons by 50%, insurer expenses would exceed insurer premiums by “only” 2.4%. This finding under what it thought was a “worst case scenario” underpinned Kaiser’s conclusion that a “premium death spiral was highly unlikely.”
This post evaluates the Kaiser analysis. I do so in part because it disagreed a bit with my own prior findings, in part because it has gotten a lot of press, and because I have had a great deal of respect for Kaiser’s analyses in general. I conclude that this Kaiser analysis rests, however, on an implausible assumption about the behavior of insurance purchasers and lacks much of a theoretical foundation. Once one eliminates this implausible assumption and employs a better theory of insurance purchasing, the threat of a death spiral becomes larger.
The reason for all this is a little complicated but try to bear with me and I will do my best to explain the problem. Essentially, what Kaiser did was to run its simulation simply by lopping off people under the age of 34 and assuming that, for some reason, the disinclination of people to purchase health insurance on an Exchange would magically stop at age 34. Thus, if an enrollment of, say, 2 million had been projected to come 800,000 from people age 18-34, 600,000 from middle aged people and 600,000 from the oldest group of enrollees, the “worst case” scenario Kaiser created (Scenario 2) would reduce enrollment to 1.6 million by having 400,000 come from people age 18-34, 600,000 from middle aged people, and 600,000 from the oldest group of enrollees. Thus, the youngest group would now constitute 25% of enrollees rather than 40%, and the other groups would constitute 37.5% of enrollees rather than 30%.
Although there is often nothing automatically wrong with this sort of “back of the envelope computation” — I have done many of them myself — sometimes they give answers that are wrong in a meaningful way. And sometimes “meaningful” means a difference of just a few percentage points. Thus, although the difference between 0.045 and 0.024 is not large on an absolute scale, this is one of these instances in which there could be a big difference between predicting premium increases augmented by 2.4% due to this particular form of adverse selection and predicting a premium increases augmented by 4.5% due to this particular form of adverse selection. The first might be too small to lead to a quick adverse selection death spiral; the second, particularly if it combined with other factors increasing premiums, might be enough to start a problem. Death spirals are a non-linear phenomenon a little like the “butterfly effect” in which small changes at one point in time can cascade into very large changes later on. What I feel comfortable saying is that the additional risk of a death spiral created by disproportionate enrollment of the an older demographic is greater than Kaiser asserts.
By simply lopping off the number of people under 35 who would enroll, the Kaiser model lacked a good theoretical foundation. The model Kaiser should have run — “Scenario 3” — is one in which the rate of enrollment is a sensible function of the degree of age-related subsidy (or anti-subsidy). Their two other scenarios could then be seen as special cases of that concept. Had they run such a “Scenario 3”, as I will show in a few paragraphs, the result is somewhat different.
Let me give you the idea behind what I think is a better model. I’m going to present the issue without the complications created by the messiness of data in this field. We need, at the outset to know at least two things: (1) the number of people of each age who might reasonably purchase health insurance if the subsidy were large enough (the age distribution of the purchasing pool); and (2) the subsidy (or negative subsidy) each person receives for purchasing health insurance as a function of age. By subsidy, I mean the ratio between the expected profit the insurer makes on the person divided by the expected expenses under the policy, all multiplied by negative one. The bigger the subsidy, the more money the insurer loses and the more likely the person is to purchase insurance.
Suppose, then, that the probability that a person will purchase health insurance is an “enrollment response function” of this subsidy. For any such enrollment response function, we can calculate at least three items: (1) the total number of people who will purchase insurance; (2) the age distribution of purchasers (including the “young invincible percentage” of purchasers between ages 18 and 35); and (3) — this is the biggie — the aggregate return on expenses made by the insurer. Thus, some enrollment response function might result in 6.6 million adults purchasing insurance of whom 40% were “young invincibles” that generated a 1% profit for the insurer on adults while another enrollment response function might result in 2.9 million adults purchasing insurance of whom 20% were “young invincibles” that generated a 3% loss for the insurer on adults.
What we can then do is to create a family of possible enrollment response functions drawn from a reasonable functional form and find the member of that family that generates values matching the “baseline assumptions” made by both Kaiser and, apparently, by HHS about total enrollment and about the “young invincible percentage.” We can then calculate the aggregate return of the insurer on adults and call this the baseline return. What we can then do is assume different total enrollments and different young invincible percentages, find the member of the enrollment response function family that corresponds to that assumption, and then calculate the new revised return on adults. The difference between the baseline return and the new revised return on adults can be thought of as the loss resulting from this form of adverse selection. There are a lot of simplifications made in this analysis, but it is better, I believe, than either the back of the envelope computation by Kaiser that has gotten so much press and, frankly, the back of the envelope computation I did earlier on this blog.
Here’s a summary of the results. When I (1) use the Kaiser/HHS age binning of the uninsured and indulge the simplifying assumption that the age distribution is uniform within each bin; (2) use Kaiser’s own estimate of the subsidy received by each age, (3) assume 7 million total purchasers ; and (4) assume 40% young invincibles with uniform age distribution within age bins, I find that the baseline return on adults is 1.0%. When I modify assumption (3) to have 3 million total purchasers and, as Kaiser did in Scenario 2, modify assumption (4) to have 20% young invincibles, the baseline return on adults is -3.5%. Thus, a better computation of Kaiser’s worst case scenario is not a reduction in insurer profits of 2.4%, but rather a reduction of 4.5%.
The graphics here compare enrollment rates, the age distribution of enrollees and various statistics for the baseline scenario and the scenario in which there are 3 million total purchasers and approximately 20% young invincibles.
Comparison of baseline scenario v. worst case using better assumptions
Various scenarios showing changes in insurer profits due to different enrollment response functions
Please note that the computations engaged in here essentially ignore those under the age of 18. This is unfortunate, but I do not have the data on the expected premiums and expenses of children. It does not look as if Kaiser had that data either. Since children are expected to comprise only a small fraction of insured persons in the individual Exchanges, however, this omission probably does not change the results in a major way.
A humbling thought
The more I engage in this analysis, the more I realize how difficult it is. There are data issues and, more fundamentally, behavioral issues that we do not yet have a good handle on. Neither my model nor Kaiser’s model can really explain, for example, why, as has recently been noted, enrollment rates are so much higher in states that support the ACA by having their own Exchange and with Medicaid expansion than in states that more greatly oppose the ACA. As I have suggested before, there is a social aspect and political aspect to the ACA that is difficult for simple models to capture. Moreover, as I noted above, this is an area where getting a number “close to right” may not be good enough. Premium increases of, say, 9% might not trigger a death spiral; premium increases of 10% might be enough. And neither my nor anyone else’s social science, I dare say, is precise enough to distinguish between 9% and 10% with much confidence.
So, longer though it makes sentences, and less dramatic as it makes analyses and headlines, the humbling truth is that we can and probably should engage in informed rough estimates as to the future course of the Affordable Care Act, but it is hard to do much more as to many of its features. I wish everyone engaged in this discussion would periodically concede that point.
Other Problems with Kaiser
There are other issues with the Kaiser analysis. Let me list some of them here.
Even accepting Kaiser’s analysis premium hikes would likely be more than 2%
Kaiser’s discussion of insurer responses to losing money is inconsistent. Look, for example, at this sentence in the report: “[i]f this more extreme assumption of low enrollment among young adults holds, overall costs in individual market plans would be about 2.4% higher than premium revenues.” Kaiser further reports “Insurers typically set their premiums to achieve a 3-4% profit margin, so a shortfall due to skewed enrollment by age could reduce the profit margin of insurers substantially in 2014.” I don’t have a quarrel with this sentence. But then look at what the Kaiser report says. “But, even in the worst case, insurers would still be expected to earn profits, and would then likely raise premiums in 2015 to make up the shortfall,” No! According to Kaiser’s own work, “even in the worst case,” insurer costs would be 2.4% greater than premium revenues. Since there is little float in health insurance and investment return rates are low these days, insurers would likely not earn profits. Then it gets worse. “However, a one to two percent premium increase would be well below the level that would trigger a “death spiral.” Perhaps so, but if insurers need to earn 3-4% to keep their shareholders happy and they are losing 1-2%, a more logical response would not be a 1-2% increase in premiums but a 4-6% increase. And, as Kaiser points out, larger premium increases could trigger a premium death spiral in part because death spirals are like avalanches: they start out small, only a little snow moves, but once the process starts it can become very difficult to abort.
Logical Fallacies
The first paragraph of Kaiser’s report asserts: “Enrollment of young adults is important, but not as important as conventional wisdom suggests since premiums are still permitted to vary substantially by age. Because of this, a premium “death spiral” is highly unlikely.” Even if the first sentence of this quote were correct — a point on which this entry has cast serious doubt — the second sentence does not follow. To use a sports analogy, it would be like saying that, the role of a baseball “closer” is important but not as important as conventional wisdom suggests. Therefore the Houston Astros, who lack a good closer, are highly unlikely to lose. No! There are multiple factors that could cause an adverse selection death spiral. Just because one of them is not as strong as others make out, that does not mean that a death spiral is unlikely. That’s either sloppy writing or just a pure error in logic.
Other Factors
And, in fact, if we start to look at some of those other factors, the threat is very real. As discussed here in more depth, I would not be surprised if adverse selection based on completely unrated gender places as much pressure on premiums as adverse selection based on imperfectly rated age. And, as I have discussed in an earlier blog entry, the transitional reinsurance that somewhat insulates insurers from the effects of adverse selection will be reduced in 2015. This will place additional pressure on premiums.
And, on the other hand, the individual mandate, assuming it is enforced, will triple in 2015 and risk adjustment measures in 42 U.S.C. § 18063, will likely provide greater protection for insurers. These two factors are likely to dampen adverse selection pressures.
Notes on Methodology
There are a number of simplifying assumptions made in my analysis. Some of them are based on data limitations. Here are a few of what I believe are the critical assumptions.
1. Functional form: I experimented with two functional forms, one based on the cumulative distribution function of the logistic distribution and the other based on the cumulative distribution function of the normal distribution. These are both pretty conventional assumptions and make sure that the enrollment rate stays bounded between 0 and 1. The results did not vary greatly depending on which family of functions the enrollment response functions were drawn from.
2. Uniform distribution of ages within each age bin of potential purchasers. I believe this is the same assumption made by Kaiser and it results from the absence of any more granular data on the age distribution of the uninsured that I was able to find.
3. The enrollment rate depends on the subsidy rate standing alone and not other possibilities such as subsidy rate and age. The data on enrollment rates is very sparse and so it is difficult to use very complex functions. Perhaps a more complex analysis would assert that enrollment depends on both subsidy rate and age, since age may be a bit of a proxy for the variability of health expenses and thus of risk.
The State of California is doing neither the best nor the worst when it comes to enrolling people in individual healthcare plans on its Exchange (Covered California), but it is doing the best job I have seen in releasing detailed information. In particular, it has released detailed information on the the age distribution of enrollees, “metal tiers” being selected by enrollees, subsidization rates, and the distribution of enrollees among insurance companies, and rates of enrollment among different language groups. Let’s look at the data and see what can be learned. And, other states, would you please do what California is doing. You have the data. It’s not that hard to put out the numbers.
Age Distribution
As shown in the paired bar graph below, the distribution of enrollees in individual Exchange plans by age in California is weighted far more heavily towards those in the older age brackets. There is, in particular, a dearth of children relative to the large numbers in the population and a disproportionately high number of those in the 55-64 age bracket.
Distribution of enrollees by age in California
The graphic here is less “bullish” on the enrollment of younger enrollees than Covered California would like to make it appear. This is because in various press releases, Covered California has been comparing the proportion of younger people enrolled against the proportion of younger people in the population and suggesting that they are similar. But this is highly misleading because the relevant statistic is the proportion of younger people in the eligible population. The elderly are not eligible to purchase policies on the Exchange. Thankfully, however, California has released the raw data that lets people do their own analyses. When the results are examined properly, in my opinion, the distribution of the young is more problematic.
Metal Tier Distribution
As noted in an earlier blog entry, a high proportion of purchases of Gold and Platinum policies could be worrisome because those policies are likely to be disproportionately purchased by those in poorer health. These policies generally have significantly less cost sharing than the Bronze and Silver policies. The chart below, taken from data provided by Covered California, shows that this concern has not materialized thus far in California. “Sub.” in the graphic shows policies that are eligible for subsidy under 26 U.S.C. § 36B and possibly under 42 U.S.C. § 18071 whereas “Unsub.” shows policies that are not eligible for subsidy. Silver is by far and away the most popular plan selected. And, contrary to earlier information released by California, which initially got matters backwards, subsidized policies are significantly more prevalent than unsubsidized ones.
Distribution of California enrollees by metal tier
Insurer Distribution
The pie chart below shows the distribution of enrollees by insurer. As one can see, enrollment in California has been dominated by large insurers. The top 4 insurers have 96.2% of the market. No small insurers have broken into the top 4. Moreover, some insurers are likely to have problems with the small absolute size of their pool if it does not increase significantly: Valley Health Plan has just 122 people enrolled to date in its health plans; Contra Costa Health Plan has just 178.
Distribution of California enrollees by insurer
Language Distribution
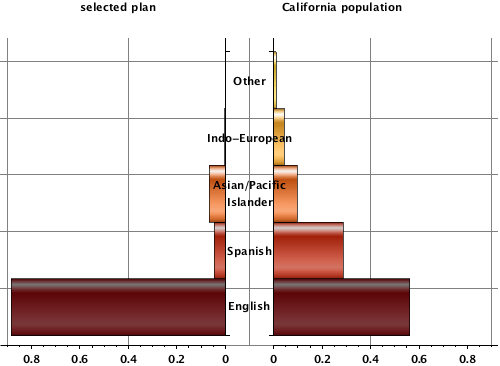
California has released information the primary language of enrollees. As shown in the paired bar graph below, the data demonstrates that English speaking individuals are enrolling at a rate significantly higher than those whose primary language is something else. People whose primary language is Spanish, for example, constitute 28.8% of the California population but only 4.6% of persons who have enrolled to date.
Distribution of California enrollees by primary language
Exploring the likely implosion of the Affordable Care Act