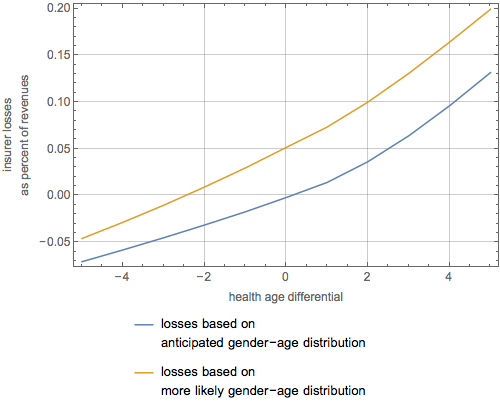
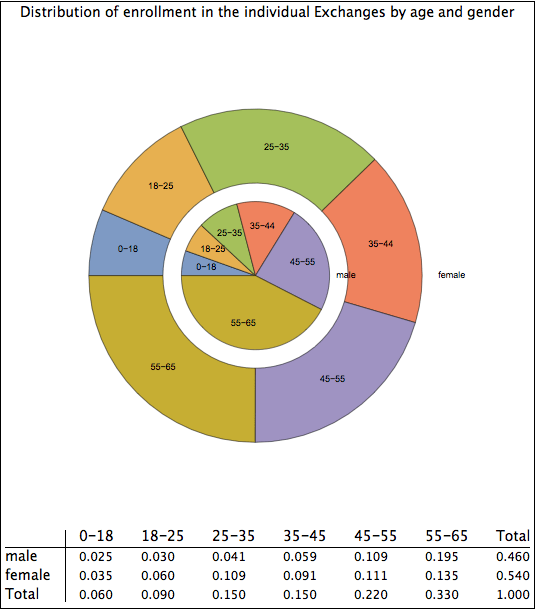
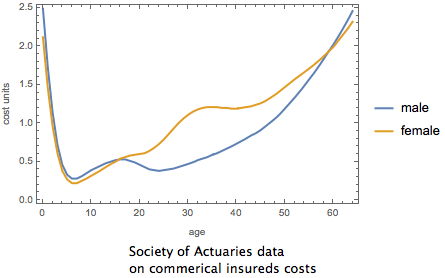
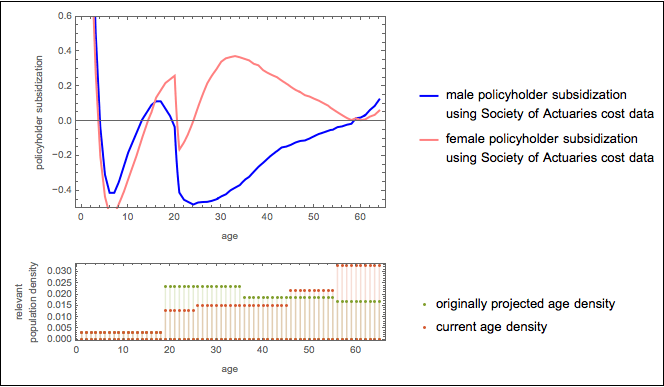
Data released yesterday at healthcare.gov shows the beginnings of an adverse selection death spiral that threatens the stability of the system of insurance created by the Affordable Care Act. The data shows that, on plans using the “federally facilitated marketplace” created under the ACA, PPO plans that continued from 2015 to 2016 increased gross premiums an average of 16% and Gold and Platinum plans increased 15% and 21% respectively. HMO plans, by contrast, increased a lesser 8% and Bronze and Silver Plans increased a lesser 12% and 9% respectively. We should thus expect to see in 2016 relatively fewer people purchasing plans that give them a greater choice in physicians or that provide greater protection against medical expenses.
The tables below summarize the big picture. The first table shows the mean change in gross premiums between 2015 and 2016 for plans that persisted over that timespan when grouped by metal level. As one can see the more generous Gold and Platinum plans increased at rates considerably higher than the less generous Catastrophic, Bronze and Silver plans.
| MetalLevel | percent change | |
|---|---|---|
| 1 | Bronze | 12.1 |
| 2 | Catastrophic | 8.1 |
| 3 | Gold | 15.2 |
| 4 | Silver | 9.4 |
| 5 | Platinum | 20.9 |
| mean change in premiums between 2015 and 2016 for 6,699 persistent plans | ||
The second table shows the mean change in premiums between 2015 and 2016 for plans that persisted over that timespan when grouped by plan type. As one can see the PPO plan, which offers the greatest choice of doctor, increased at a higher rate than other types of plans. EPOs, which are similar to HMOs but restrict visits to specialists less, increased in gross premiums at a rate far higher than HMOs.
| PlanType | percent change | |
|---|---|---|
| 1 | POS | 12.3 |
| 2 | HMO | 8.3 |
| 3 | EPO | 12.2 |
| 4 | PPO | 16.5 |
| mean change in premiums between 2015 and 2016 for 6,699 persistent plans | ||
The third table combines the first two and shows, for each combination of metal level and plan type, the mean percentage increase in gross premiums between 2015 and 2016.
| MetalLevel | HMO | EPO | POS | PPO | |
|---|---|---|---|---|---|
| 1 | Catastrophic | 1.9 | 5.8 | 6.9 | 14.8 |
| 2 | Bronze | 11.2 | 10.9 | 12.0 | 16.2 |
| 3 | Silver | 5.8 | 8.8 | 12.5 | 14.5 |
| 4 | Gold | 9.4 | 16.6 | 17.1 | 19.7 |
| 5 | Platinum | 12.2 | 25.6 | 7.5 | 25.9 |
| mean change in premiums between 2015 and 2016 for 6,699 persistent plans | |||||
Premium increases are only part of the story, however. Some types of plans are not available at any price any longer. The table below shows the percentage of rating areas in 2015 and 2016 containing each type of plan. Notice that the percent of rating areas containing any PPO has dropped significantly between 2015 and 2016; HMOs and POS plans have dropped as well, though EPO plans have become more prevalent.
| PlanType | AVG2015 | AVG2016 | |
|---|---|---|---|
| 1 | HMO | 92.6 | 88.6 |
| 2 | EPO | 78.3 | 82.5 |
| 3 | POS | 83.7 | 75.4 |
| 4 | PPO | 92.5 | 76.7 |
| percent of rating areas having at least one of these plan types | |||
We can also consider the prevalence of competition. The table below shows the percentage of rating areas in 2015 and 2016 containing at least two of each type of plan. Notice that with PPOs, the percentage of rating areas with competition has declined, although it has increased somewhat for HMOs, EPOs and POS plans.
| PlanType | AVG2015 | AVG2016 | |
|---|---|---|---|
| 1 | HMO | 71.3 | 72.5 |
| 2 | EPO | 66.5 | 74.0 |
| 3 | POS | 48.2 | 50.6 |
| 4 | PPO | 76.0 | 61.0 |
| percent of rating areas having at least two of these plan types | |||
The same analysis can be done on the metal levels of the plans available. The table immediately below shows for 2015 and 2016 the percentage of rating areas in which there is at least one plan of the specified metal level. Platinum plans have declined sharply in prevalence since 2015. Now only just over half of the rating areas have even a single platinum plan available even if one were willing and able to pay the higher premiums.
| MetalLevel | AVG2015 | AVG2016 | |
|---|---|---|---|
| 1 | Catastrophic | 74.3 | 72.2 |
| 2 | Bronze | 91.8 | 88.1 |
| 3 | Silver | 91.1 | 89.7 |
| 4 | Gold | 90.9 | 88.5 |
| 5 | Platinum | 92.7 | 53.2 |
| percent of rating areas having at least one of these metal levels | |||
When it comes to competition, the picture is even worse for platinum plans. In only about a third of the rating areas can one choose between platinum plans.
| MetalLevel | AVG2015 | AVG2016 | |
|---|---|---|---|
| 1 | Catastrophic | 33.5 | 30.3 |
| 2 | Bronze | 82.5 | 82.4 |
| 3 | Silver | 85.7 | 84.6 |
| 4 | Gold | 73.0 | 73.4 |
| 5 | Platinum | 44.9 | 34.6 |
| percent of rating areas having at least two of these metal levels | |||
Finally, since it seems to be the PPO plans whose prevalence is declining most, we can show the extent of that prevalence according to the metal level of the plan. The table below shows that the Platinum PPOs, the plan probably most helpful to the chronically ill that the ACA was supposed to help greatly, is diminish significantly in prevalence but that Gold and Silver PPOs are diminishing as well
| PlanType | MetalLevel | AVG2015 | AVG2016 | |
|---|---|---|---|---|
| 1 | PPO | Catastrophic | 85.8 | 71.1 |
| 2 | PPO | Bronze | 94.9 | 81.6 |
| 3 | PPO | Silver | 94.9 | 81.6 |
| 4 | PPO | Gold | 94.9 | 81.6 |
| 5 | PPO | Platinum | 89.5 | 53.5 |
| percent of rating areas having at least one of these Platinum plan types | ||||
Conclusion
The data shows that platinum plans and PPO plans are shrinking in prevalence and that the gross premiums for such plans are going up. One might say that this development is not so awful since it leaves in place a market for more basic plans: HMO plans for example or silver and gold plans. Perhaps the government should not be subsidizing individual’s choice of doctors or fostering plans, such as platinum plans, that fail to deter excess medical consumption. Such is not, however, the promise of the ACA or, I suspect, the desires of many of its proponents.
Moreover, we are in a dynamic situation. Think about next year when the insurer subsidies are supposed to disappear and when the chronically ill people who were in platinum and/or PPO plans migrate into the next best thing, a gold plan or, if one is available, a POS or EPO plan. Suddenly those plans become vulnerable to adverse selection pressures. And for 2017 we might thus expect to see yet further shrinkage of PPO and platinum plans and greater pressures on everything but the basic Bronze and Silver HMO plans. When that happens, the adverse selection death spiral will not only start biting wealthier purchases or those with chronic conditions, but mainstream America. Private health insurance is fragile. It generally does not well withstand the sort of underwriting regulation imposed by the ACA. The conceit of the ACA proponents was that they had engineered a system — the “three legged stool” so strong that it could resist the almost invariable pressures of adverse selection. If I am right, and regardless what one thinks about the motives of those proponents, we are beginning to see that the engineering was just not good enough.
Caveats and further research
The computations shown above are based on the number of plans and not weighted by the number of enrollees. This is largely of necessity since the federal government has not been releasing enrollment figure by plan in a clear way (although it may be possible to tease the figures out of rate review submissions filed and collated on healthcare.gov). Although enrollment weighting will likely decrease the average mean premium (less expensive policies tend to be purchased more), it is not clear that enrollment weighting will have much effect on relative premium increases.
The figures are also not computed yet on a state-by-state basis, something that I hope to present in a later post. They also contain only data for states whose plans are described in material available at healthcare.gov. Data for states such as California and New York, which have their own exchanges, is not included here and might alter the numbers somewhat.
Finally, I present gross premiums here; as I have discussed at length elsewhere, net premium increases may well be higher, particularly where the purchaser wishes to retain a gold or platinum plan or a PPO plan whose premiums are rising even faster than those of the silver plans and the second lowest silver plan. The situation is worst where, due to some willingness on the part of a new entrant to take risk, the second lowest silver plan drops in price, thereby decreasing subsidy levels, but other silver, gold and platinum plans increase in price.
Note
Programming for this work was done in R using data from data.healthcare.gov and is available on request from the author. Packages used include data.table, tidyR, htmlTable and dplyr. There is a lot more work to be done mining these databases.