The short answer: concerned but not panicked
As discussed yesterday on this blog and elsewhere in the media, Cover California, the state entity organizing enrollment there, has released data showing the age distribution of the group thus far enrolling in plans on its Exchanges. Although I took a rather cautionary tone about the age distribution — fearing it could stimulate adverse selection — the head of Cover California and some influential media outlets generally favorable to the Affordable Care Act have been considerably more cheerful. So, who’s right? For reasons I will now show — and probably to no one’s surprise — me. (More or less).
To do this, we need to do some math. It’s a more sophisticated variant of the back of the envelope computation I undertook earlier on this blog. The idea is to compute the mean profit of insurers in the Exchange as a function of the predicted versus the actual age distribution of the pool they insure. Conceptually, that’s not too difficult. Here are the steps.
1. Compute the premium that equilibrates the “expectation” of premiums and costs for the predicted age distribution of the pool they insure. Call that the “predicted equilibrating premium.”
2. Compute the expected profit of the insurer given the predicted equilibrating premium and the actual age distribution of the pool they insure.
3. Do Step 1 and Step 2 for a whole bunch (that’s the technical term) of combinations of predicted age distributions and actual age distributions.
Moving from concept to real numbers is not so easy. The challenge comes in getting reasonable data and, since there are an infinite number of age distributions and in developing a sensible parameterization of some subset of plausible distributions.
The Data
The data is interesting in and of itself. To get the relationship between premiums and age, I used the robust Kaiser Calculator. Since healthcare.gov itself recommends the web site (their own site seems to have a few problems) and I have personally validated its projected premiums for various groups against what I actually see from various vendors, I believe it is about as reliable a source of data as one is likely to find anywhere right now. So, by hitting the Kaiser Calculator with a few test cases and doing a linear model fit using Mathematica (or any other decent statistics package), we are able to find a mathematical function that well captures a (quadratic) relationship between age and premium. (The relationship isn’t “really” quadratic, but quadratics are easy to work with and fit the data very well.) The graphic below shows the result.

We can normalize the graphic and the relationship such that the premium at age 18 (the lowest age I consider) is 1 and everything else is expressed as a ratio of the premium at age 18. Here’s the new graphic. The vertical axis is now just expressed in ratios.

To get the relationship between cost and age, I used a peer reviewed report from Health Services Research titled “The Lifetime Distribution of Health Care Costs.” It’s from 2004 but that should not matter much: although the absolute numbers have clearly escalated since that time, there is no reason to think that the age distribution has moved much. I can likewise do a linear model fit and find a quadratic function that fits well (R^2 = 0.982). Again, I can normalize the function so that its value at age 18 is 1 and everything else is expressed as a ratio of the average costs incurred by someone at age 18. Here’s a graphic showing the both the relationship between age and normalized premiums in the Exchanges under the Affordable Care Act and normalized costs.
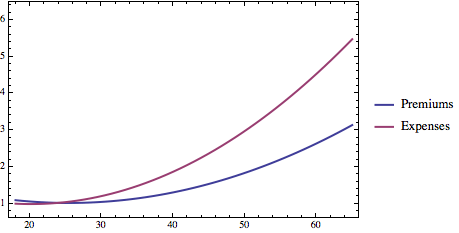
The key thing to see is that health care claims escalate at a faster rate than health care premiums. Others have noted this point as well. They do so because the Affordable Care Act (42 U.S.C. § 300gg(a)(1)(A)(iii)) prohibits insurers from charging the oldest people in the Exchanges more than 3 times what they charge the youngest people. Reality, however, is under no such constraint.
Parameterizing the Age Distribution
There are an infinite number of potential age distributions for people purchasing health insurance. I can’t test all of them and I certainly can make a graph that shows profit as a function of every possible combination of two infinite possibilities. But, what I can do — and rather cleverly, if I say so myself — is to “triangulate” a distribution by saying how close it is to the age distribution of California as a whole and how close it is to the age distribution of those currently in the California Exchange pool. I’ll say a distribution has a “Pool Parameter Value” of 0 if it comes purely from California as a whole and has value of 1 if it comes purely from the California Exchange pool. A value of 0.4 means the distribution comes 40% from California as a whole and 60% from the current California Exchange pool. The animation below shows how the cumulative age distribution varies as the Pool Parameter Value changes.

Equilibration and Results
The last step is to compute a function showing the equilibrium premium as a function of the predicted pool parameter value. We can then use this equilibrating premium to compute and graph profit as a function of both predicted pool parameter value and actual pool parameter value.
The figure below shows some of the Mathematica code used to accomplish this task.

Stare at the graphic at the bottom. What it shows is that if, for example, California insurers based their premiums on the pool having a “parameter value” of 0 (looks like California) and the actual pool ends up having a “parameter value of 1 (looks like the current pool), they will, everything else being equal, lose something like 10% on their policies and probably need to raise rates by about 10% the following year. If, on the other hand, they thought the pool would have a parameter value of 0.5 and it ended up having a parameter value of 0.75 the insurers might lose only about 3.5%.
Bottom Line
If I were an insurer in California I’d be concerned about the age numbers coming in, but not panicked. First, I hope I did not assume that my pool of insureds would look like California as a whole. I had to assume some degree of adverse selection. But it does not look as though, even if I made a fairly substantial error, the losses will be that huge. That’s true without the Risk Corridors subsidies and it is all the more true with Risk Corridor subsidies.
What I would be losing sleep about, however, is that the pool I am getting is composed disproportionately of the sick of all ages. If I underestimated that adverse selection problem, I could be in deep problem. My profound discomfort would arise because, while I get to charge the aged somewhat more, I don’t get to charge the sick anymore. And there’s one fact that would be troubling me. Section 1101 of the Affordable Care Act established this thing calledthe Pre-Existing Condition Insurance Pool. It’s been in existence (losing boatloads of money) for the past three years. It held people who couldn’t get insurance because they had pre-existing conditions. They proved very expensive to insure. There are 16,000 Californians enrolled in that pool. But that pool ends on January 1, 2014. And the people in it have to be pretty motivated to get healthy insurance. Where are they going to go? If the answer is that a good chunk of the 79,000 people now enrolled in the California pool are former members of the PCIP, the insurers are in trouble unless they get a lot more healthy insureds to offset these individuals.
