The Congressional Budget Office just issued a report that assumes the Affordable Care Act system of individual policies sold in Exchanges without medical underwriting can remain relatively stable. Tightly bound up with that assumption is its prediction about a controversial ACA program known as “Risk Corridors” that requires profitable insurers to pay the federal government up to 80% of profits they make on policies sold on the Exchanges but that also requires the federal government to pay insurers up to 80% of the losses they suffer from policies sold on the Exchanges. The CBO now believes it has enough information to predict that Risk Corridors will actually make money — $ 8 billion over three years — for the government at the expense of insurers.
This CBO prediction of $8 billion in federal revenue, which has gained much publicity, pulls the rug out from critics of the ACA such as Senator Marco Rubio who have introduced legislation that would repeal Risk Corridors as an insurance industry “bailout.” Such a blunting of Senator Rubio’s proposed repeal legislation is crucial in the ongoing battle over the ACA because repeal of Risk Corridors could result in insurers (who just might not believe the CBO’s numbers) exiting the Exchanges for fear of having no government protection against losses resulting from unfavorable experiences in the new market the government has created. On the other hand, if the CBO is just getting its number wrong, Rubio’s case for repeal of Risk Corridors remains as strong (or problematic) as it ever was. The CBO projection is also important because Risk Corridors nets the government money if and only if the ACA works, insurers are able to make some profits, and a death spiral never takes hold. And this, as readers of this blog are aware, is a prediction about which many have serious doubts.
Here’s the short version of the rest of this post.
I’ve done the math and I don’t see how the CBO is getting this $8 billion number unless it is assuming either very high enrollment in policies covered by Risk Corridors or very high rates of return made by insurers. Or it made a mistake. I don’t think the CBO’s own numbers support very high enrollment in policies covered by Risk Corridors and I don’t believe either an emerging reality or the CBO’s own rhetoric justify assuming very high rates of return. So I think the CBO ought to take a second look at its prediction. People should not yet make policy decisions based on the CBO estimate.
Reader, you now have a choice. I’m afraid that the next several paragraphs of this post become very technical. It’s kind of forensic mathematics in which one attempts to use statistics and numerical methods to deduce the circumstances under which something said could be true. If that sounds dreadful, scary or tedious, I would not protest too loudly were you to skip ahead to the section titled “How could I be wrong?” Before you leave, however, realize that what I am attempting to accomplish in the part you skip is a form of proof by contradiction. I prove that if what the CBO was saying were true, then insurers would have to be making 8% profit. But nobody, including the CBO thinks they will make 8% profit, so the $8 billion number can’t be right.
On the other hand, dear reader, if you liked the Numb3rs television show (including my minor contributions thereto) or math or detective work or just care a lot about the Affordable Care Act, the rest of this post is for you. What I am about to discuss is not only exciting math, but also the soul of the Affordable Care Act — whether the individual Exchanges without medical underwriting can remain relatively stable.
Forensic mathematics in action
Conceptually, here’s the calculation one needs to do. What we want to figure out is the distribution of insurer profits (measured as a ratio of expenses divided by premium revenues) upon which the CBO must be relying. I assume the CBO is using a member from the “Normal” or “Lognormal” family of distributions because those are typical models of financial returns and there is little reason to think that the distributions of insurer profits (expenses minus revenues) will materially depart from those assumptions. To continue reading this post, you don’t have to know exactly what those distributions are except that they look for our purposes like the “bell curves” you have seen for many years. I’ve placed a graphic below showing some normal (blue) and lognormal (red) distributions. Although it should not matter all that much, I’m going to use a lognormal distribution from here on in because the ratio of insurer expenses to premiums should never be negative and the lognormal distribution, unlike its normal cousin, never takes on negative values.

The problem is that there are an infinite number of lognormal distributions from which to choose. How do we know which distribution the CBO is emulating in its computations? How do we know just how positive the CBO assumes the individual Exchange market is going to be on average or how dispersed insurer profits are going to be? As it turns out, the complexity of the lognormal distribution can be characterized with just two “parameters” often labeled μ (mu, the mean of the distribution) and σ (sigma, the standard deviation of the distribution). Once we have those two parameters (just two numbers), we can deduce everything we need about the entire distribution.
Now, to solve for two parameters, we often need two relationships. And, thoughtfully, the CBO has given us just enough information. It has told us how much money in total it intends to raise from Risk Corridors ($8 billion) and the ratio (2:1) between money it collects from profitable insurers and the money it pays out to unprofitable insurers. These two facts help constrain the set of permissible combinations of Risk Corridor populations (the number of people purchasing policies in plans subject to the Risk Corridor program) and insurer profitability distributions. What I want to show is that it takes an extremely high Risk Corridor population in order to get rates of return that are not way larger than most people — including the CBO — think likely to occur.
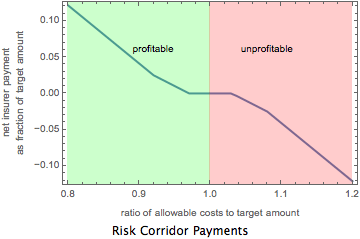
I first want to calculate the amount of money insurers would pay to HHS under the Risk Corridors program if the total amount of premiums collected were $1. Some of the payments — those by highly profitable insurers — will be positive. Those by highly unprofitable insurers will be negative. To do this I take the “expectation” of what I will call the “payment function” over a lognormal distribution characterized by having a mean of μ and a standard deviation of σ. By payment function, I mean the relationship shown below and created by section 1342 of the ACA, 42 U.S.C. § 18062. This provision creates a formula for how much insurers pay the Secretary of HHS or the Secretary of HHS pays insurers depending on a proxy measure of the insurer’s profitability. The idea is to calculate a ratio of “allowable costs” (roughly expenses) to a “target amount” (roughly premiums). If the ratio is significantly less than 1 (and outside a neutral “corridor”), the insurer makes money and pays the government a cut. If the result is significantly greater than 1 (and outside the neutral “corridor”), the insurer loses money and receives a “bailout”/”subsidy” from the government. The program has been referred to with some justification as a kind of “derivative” of insurer profitability, the ultimate “Synthetic CDO.”
The graphic below shows the relationship contained in the Risk Corridors provision of the ACA. The blue line shows the net insurer payment (which could be negative) to the government as a function of this proxy measure of the insurer’s profitability. Ratios in the green zone represent profits for the insurer; ratios in the red zone represent losses. Results are stated as a fraction of “the target amount,” which, as mentioned above, is, roughly speaking, premium revenue.
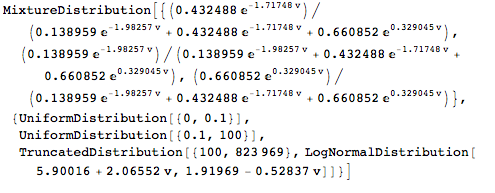
When we do this computation, we get a ghastly (but closed form!) mathematical expression of which I set out just a part in small print below. (It won’t be on the exam). I’ll call this value the totalPaymentFactor. Just keep that variable in the back of your mind.
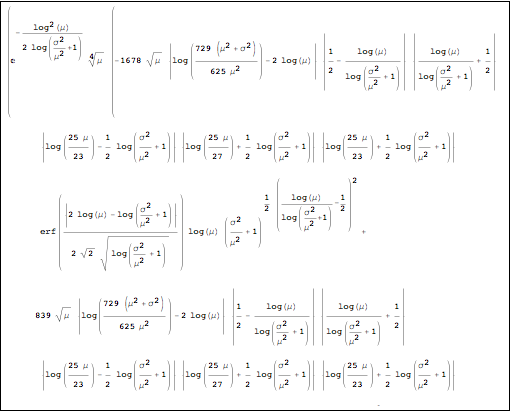
I next want to calculate the amount of payments profitable insurers will make to HHS. To do this, we truncate the lognormal distribution to include only situations where the ratio between premiums and expenses is greater than 1. Again, we get a pretty ghastly mathematical expression, a small excerpt of which is shown below. I will call it the expectedPositivePaymentFactor.

Finally, I want to calculate the amount of payments unprofitable insurers will receive from HHS. To do this, we truncate the lognormal distribution to include only situations where the ratio between premiums and expenses is less than 1. Again, we get a pretty ghastly mathematical expression, which, for those of you who can not get enough, I excerpt below. I will call it the expectedNegativePaymentFactor.

The CBO has told us in its recent report that the government will collect twice as much from profitable insurers (expectedPositivePaymentFactor) as it pays out to unprofitable ones (expectednegativePaymentFactor). We can use numeric methods to find the set of μ, σ combinations for which that relationship exists. The thick black line in the graphic below shows those combinations.

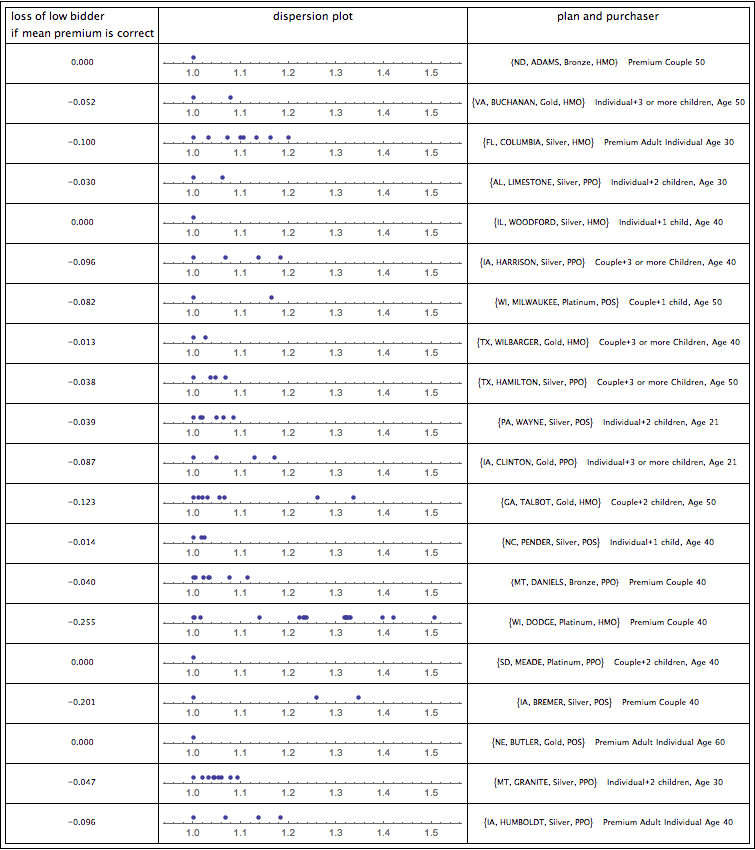
To determine which point on the black line above, which combination of the parameters μ, σ , is the actual distribution, we need to use our information about the totalPaymentFactor. The idea is to realize that the totalPaymentFactor must be equal to the quotient of the CBO’s estimated $8 billion and the total premium collected by Risk Corridor plans over the next three years. But we know that the total premium collected should be equal to the mean premium charged by the Exchanges multiplied by the number of people in Risk Corridor plans. Some math, discussed in the technical notes, suggests that the mean premium under the ACA is about $3,962. And the CBO accounts for 8 million people being in Risk Corridor plans in 2014, 15 million being in Risk Corridor plans in 2015 and 25 million being in Risk Corridor plans in 2016. This means that the total premiums collected by insurers under Risk Corridor plans over the next 3 years should be about $190.2 billion. And this in turn means that the totalPaymentFactor must be 0.042.
Ready?
It turns out that of all the infinite number of lognormal distributions there is only one that satisfies the requirements that (a) the government will collect twice as much from profitable insurers (expectedPositivePaymentFactor) as it pays out to unprofitable ones (expectednegativePaymentFactor) and (b) for which the totalPaymentFactor takes on a value of 0.042. It is a distribution in which the mean value is 0.923 and the standard deviation is 0.113. I plot the distribution below. A dotted line marks the break even point for insurers. Points to the left of the break even line correspond with profitable insurers; points to the right correspond with unprofitable insurers.

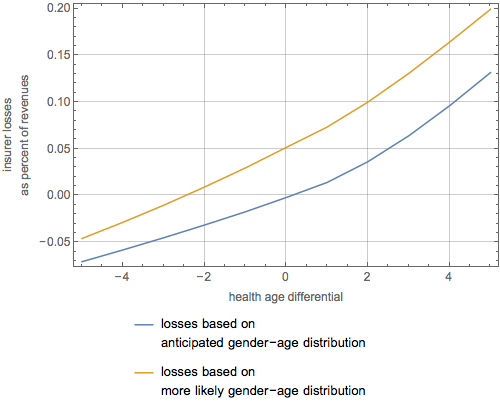
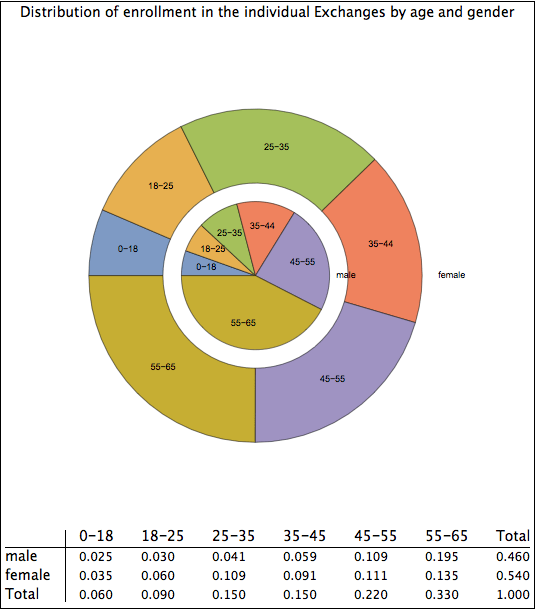
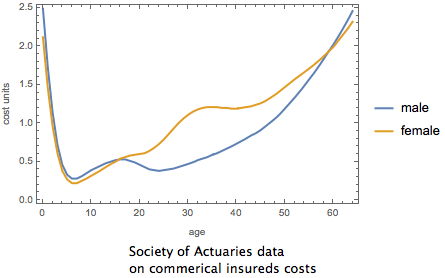
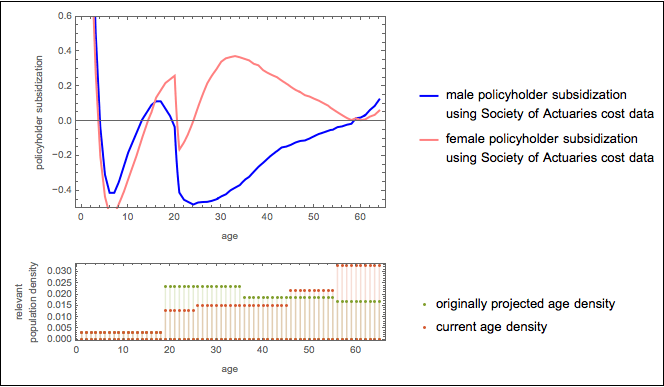
Here are some factoids about the uncovered distribution. The average insurer will have expenses that are 92.3% of premiums and the median insurer will have expenses that are only 91.6% of profits. In other words, they will be making 7.7 cent and 8.4 cents respectively on every dollar of premium they take in. For reasons discussed below, this is a difficult figure to accept. It is particularly difficult in light of the pessimistic news that is emerging about things such as the age distribution of enrollees , reports from Deutsche Bank that one of the largest insurers in the Exchanges, Humana, expects to receive (not pay!) a lot of money under the Risk Corridors program, the hardly exuberant forecasts of other publicly traded insurers about the ACA, and the recent general downgrading of the insurance sector by Moody’s partly because of the ACA.
Implicit in my finding about the most likely distribution of profitability is an assertion by the CBO that 76% of insurers will be profitable under the ACA while 24% will be unprofitable. About 17% will be sufficiently unprofitable that they will receive subsidies (a/k/a bailouts) from the federal government and 9% will be sufficiently unprofitable that their marginal losses will be covered at 80%. Only 15% of insurers will be “inside” the risk corridor and neither pay nor receive under the program.
How could I be wrong?
I feel confident that I’ve done the ” gory math part” of this blog post correctly. Mathematica, which is the software I’ve used to do the integral calculus and the numeric components involved just does not make mistakes. I also feel pretty confident that I understand how the Risk Corridors program works under section 1342 of the ACA. That’s kind of my day job. And so, readers who skipped down to this part, I do believe that if the CBO were right about the $8 billion, that could only happen if insurers were, on average, earning an implausible 8% in the Exchanges.
If I’m wrong, then, it is because, except for the little issue I will mention at the end, I have made bad assumptions about the total premiums insurers expect to collect over the next three years in policies covered by Risk Corridors. That error could come from two sources. I could have the mean premium per policy wrong or I could have the relevant enrollment wrong. Let’s look at each of these.
Could I be wrong about the mean premium?
I computed the mean premium in the computation above by using data collected by the Kaiser Family Foundation on the ratio of premiums by age under most insurance plans and the typical Silver plan premium for a 21 year old (non-smoker). I then used the original forecast about the age distribution of insureds to compute an expected premium. I got $3,962. And this number seems very much in line with earlier HHS estimates, which were that mean premiums would be $3,936. So, I think I have the mean premium correct.
Could I be wrong about the number of people in Risk Corridor plans?
I computed the number of people enrolled in policies covered by Risk Corridors by looking at the CBO’s own figures. I’m not vouching that the CBO is right in its projections, but this is not the day to argue that point. The CBO now says (Table B-3, p. 109) that individual enrollment in the Exchanges will be 6 million, 13 million and 22 million respectively over the next three years. And it says that employment-based coverage purchased through Exchanges (which I assume are SHOP Exchanges) will be 2 million, 2 million and 3 million respectively. So , by addition, that’s where the figures I used of 8 million, 15 million and 25 million come from. I’m not aware of anyone else who would purchase a policy subject to Risk Corridors. Again, bottom line, I don’t think I’m doing anything wrong here.
The little issue at the end: Could ACA definitions be responsible for the incongruity?
The only other conceivable explanation of the divergence between the CBO figures and my analysis is that I am failing to take a subtlety of Risk Corridors into account. Remember, careful readers, that sentence earlier up that started out: “The idea is to calculate a ratio of “allowable costs” (roughly expenses) to a “target amount” (roughly premiums).” I stuck in the “roughlies” because the “allowable costs” are not exactly expenses and the “target amount” is not exactly premiums. When you look at the statute and the regulations, you can see that both of these terms are tweaked: basically you subtract administrative costs from both values. And you subtract reinsurance payments from expenses — but that makes sense because the insurer reduced premiums in anticipation of those reinsurance payments.
So, in the end, I don’t see why these subtleties should affect my analysis in any significant way. But I am not infallible. And I do pledge that if someone points out an error to me, I will dutifully assess it and report it.
Sensitivity Analysis
Out of an abundance of caution, however, I have rerun the numbers on the assumption that premium revenue from policies subject to Risk Corridors is 50% greater than my original estimate either because of an underestimate of per policy costs or a failure to understand that there is some additional group within Risk Corridors protection. When I do that, though, I find that the ratio of expenses to premiums is 0.943, meaning that insurers are still earning a pretty substantial 5.6%. Although that is more believable than the earlier figure of 7.7%, it is still pretty high.
Conclusion
To be honest, it makes me very nervous to say that the CBO did its math wrong or, worse, to accuse it of bad faith. These are intelligent, educated professionals and they have access to a lot more data and a lot more personnel than I do. Here at acadeathspiral it’s just me and my little computer along with some very powerful software. On the other hand, it’s not as if the CBO hasn’t been wrong before. It assumed earlier that the government would reduce its deficit $70 billion over 10 years as a result of Title VIII of the ACA (the so-called CLASS Act on long term care insurance) when many independent sources believed — rightly as it turned out — that the now-repealed CLASS Act was obviously structured in a way that could never fly. The CBO assumed in July 2012 that 9 million people would enroll in the Exchanges in 2014, a number that is now down to 6 million. And, while there are explanations for each of these changes, the bottom line is that CBO is fallible too.
So, if I might, I would strongly urge the CBO to double check its numbers and provide more information on the data it relied upon and the methodology it employed in getting to its results. I’d ask Congress, which has ongoing oversight of the ACA, to insist that the Congressional Budget Office, which is exempt from Freedom of Information Act requests from ordinary citizens, provide further detail. American healthcare is indeed too important to have policy decisions made on the basis of what could be some sort of mathematical error.
Really Technical Notes
- I’m using a reparameterized version of the lognormal distribution that permits direct inspection of its mean and standard deviation rather than the conventional one, which in my opinion is less informative. The explanation for doing so and the formula for reparameterization is here.
- To compute the average premium, I took the premium ratios used by the Kaiser Family Foundation, calibrated it so that a 21 year old was paying the national average payment for a silver plan purchased by a 21 year old. I then computed the expected premium over the distribution of purchase ages originally assumed by those modeling the ACA.